Design Distributed Message Queue.
Distributed Message Queue.
Benefits of message queue - Decoupling, Scalability, Performance, Availability.
Decoupling - It eliminates tight coupling between components so they can be updated independently.
Scalability - Producer and consumer can be scaled independently.
Availability - One part get offline other component can interact with the queue.
Better Performance - Asynchronous communication.
Message Queue Vs Event Streaming Platform.
Message Queue - RocketMQ, ActiveMQ, RabbitMQ, ZeroMQ.
Event Streaming platform - Kafka, Pulsar.
The difference gets blur RabbitMq a message queue added a feature to allow repeated message consumption and long message retention and uses an append-only logs like event streaming platform.
Here will design distributed message queue added feature - long data retention, repeated consumption of message.
Design Scope.
Understand the requirement.
What is the format and average size of message?
Text only. In the size of KB.
Can message be repeatedly consumed - Yes by different consumers. A traditional message queue does not retain the message once it is delivered to the consumer. The message cannot be repeatedly consumer in traditional message queue.
Are the message order same?
Yes the message should be in same order as they were produced. A traditional distributed message queue does not usually guarantee delivery order.
Data need to be persisted and data retention?
Yes data retention - 2 weeks. Added feature.
Number of producer and consumer we will support?
The more the better.
Data delivery semantic to support like at-most -once, at-least-once and exactly once. Should support at-least-once. All of them should be configurable.
Target throughput and end-to-end latency? High throughput cases like log aggregation. It should support Low latency delivery.
Functional Requirement.
Producer to consumer and message can be consumed repeatedly or at least once.
Data should be truncated.
Message size in kilobyte and in order.
Data delivery semantics configured by user.
Non Functional Requirement.
High throughput and low latency.
Scalable.
Persistent and durable.
Difference in comparison to traditional message queue.
They do not support retention data is only retain till consumer consumes it. They provide on-disk overflow capacity which is smaller than the capacity required for the event streaming platform.
It do not maintain message ordering.
High Level Design.
Producer send message to the queue and consumer subscribe to the queue and consumes the subscribed message.
Message queue in the middle perform decoupling and allowing them to operate and scale independently.
Both the producer and the consumer are the clients in the client/server model and the message queue is the server. The client and server communicated over the network.
Message Models.
The popular messaging model - point-to-point and publish-subscribe.
Point-To-Point.
It is commonly found in traditional message queue. A message sent to the queue and is consumed by one and only one consumer.
There can be multiple consumer waiting to consumer message in the queue nut each message can be consumed by a single consumer.
Point to Point Model - Message A is only consumed by Consumer 1.
When the consumer acknowledge that the message is consumed then it is removed from the queue.
Publish-Subscribe.
Topic - Messages are sent to and read from a specific topic.
Publish-Subscriber Model - Message is consumed by both consumer 1 and consumer 2.
The design support both the model. The publish-subscribe model is implemented by topic and the point-to-point model is supported by the consumer group.
Topics, Partition and Broker.
What will happen when the data volume in a topic is too large for a single server to handle?
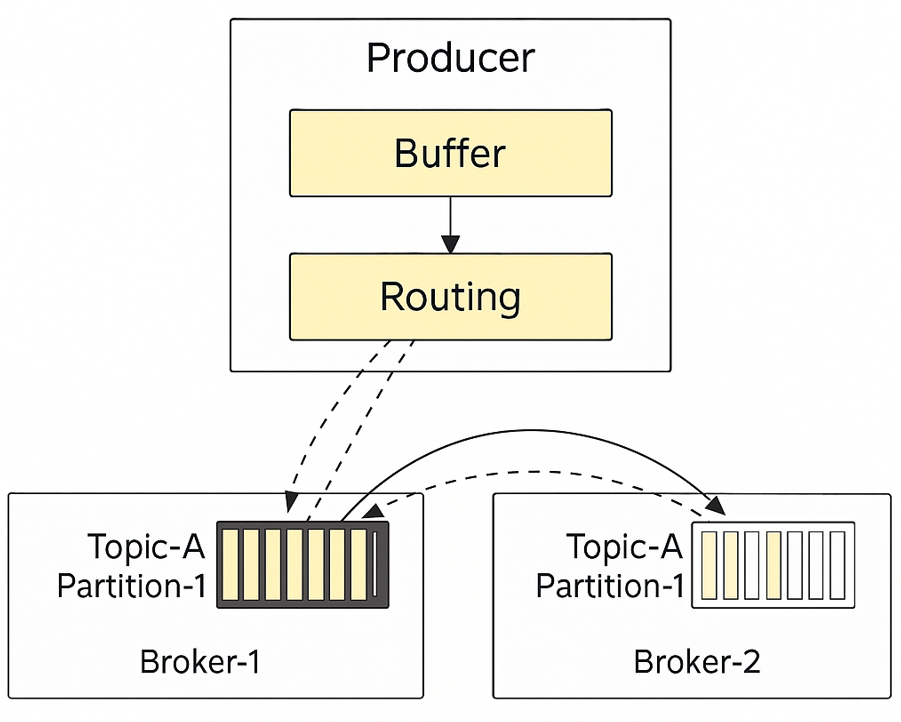
Topics are divided into partition and they are distributed across the server in the message queue cluster. The server that hold partition are called brokers. The distribution of partitions among broker is the key element to support high scalability. We can scale the topic capacity by expanding the number of partitions.
Each partition maintain the order of the message. The position of a message in the partition is called an offset.
Message send by the producer is send to one of the partition for the topic and each message has an optional message ley and all message with the same key will go to the same partition.
When a consumer subscribe to a topic it pulls data from one or more of these partition and there are multiple consumers subscribing to a topic. The consumer form a consumer group for a topic.
Message Queue.
A Consumer Group is a set of consumers working together to consume messages from the topic.
Each consumer group can subscribe multiple topics and maintain its own consuming offset. Group consumers by use case like billing and accounting.
The instance in the same group can consume traffic in parallel - Consumer group 1 subscribe to TopicA and consumer Group 2 subscribe to TopicA and TopicB.
Reading data in parallel improves the throughput but the consumption order of the message in the same partition is not guaranteed. Consumer 1 and Consumer 2 in the same consumer reading from the same partition the order will be wrong.
Consumer group maintain the offset number and not individual consumer. When one consumer get the message then the count will be changed in the consumer group.
To fix it - A single partition can only be consumed by one consumer in the same group. The number of consumer in the group is large than in comparison to the partition of a topic then some consumer will not get data from the topic.
Message in same partition are consumed by only one consumer which like the point to point model.
Partition is the smallest storage unit and we can allocate enough partition in advance to avoid the need to increase the number of partition.