Design Ad Click Event Aggregation.
Ad Click Event aggregation - meaning tracking ad click in online advertising.
Digital advertising has a core process called Real-Time Bidding RTB in which the digital advertising inventory is brought and sold.
Based on the data the company can understand which ad is expensive and mostly viewed.
The key metric used in the online advertising - click through rate CTR and conversion rate CVR.
Understand the requirement.
Input data is a log file in different servers and the latest clikc event are appended. The event has the attribute - ad_id, click_timestamp, user_id, ip and country.
Data Volume - 1 billion ad clicks per day and 2 million ads in total. The number of ad click events grows 30% every year.
The system return 3 queries - Return number of click events for a particular ads in M minutes.
Return top 100 most clicked ad in past 1 minute. Parameter and filtering are configurable. Aggregation occurs every minute.
Data filtering on the queries by ip, user_id and country.
Edge Cases - Events arrived later than expected. There might be duplicate events. Different parts of system might be down at any time consider system recovery.
Latency - Latency for RTB is lessthan one second due to the responsiveness and Ad click event aggregation latency a few minutes as it is only for ad billing and reporting.
Non-Functional Requirement.
Correctness of data is important as used for RTB and ad billing.
Properly handle delayed or duplicate events.
Rebustness - The system should be resilient to partial failures.
Latency requirement - End-to End latency should be a few minutes at most.
Back-of-the-envelope Estimation.
1 billion DAU. Assuming each user click 1 ad per day. 1 billion ad click per day.
Ad click QPS = (10^9 events)/(10^5 seconds in a day) = 10,000. Peak ad click QPS is 5 times the average number. Peak QPS = 50,000 QPS.
Single ad click event occupies 0.1KB storage. Daily storage requirement 0.1KB X 1 billion = 100GB. The monthly storage requirement is 3TB.
High Level Design.
Query API Design.
The dashboard used by data engineer should give detail of the ad.
Aggregate the number of click of ad_id in last M minute.
Return top N most clicked ad_id in last M minute.
Support aggregation filtering by different attributes.
There will be 2 API and filtering is done vy adding query parameter to the requests.
Aggregate the number of ad_id in last M minute.
GET /v1/ads/{:ad_id}/aggregated_count Return aggregated event count of the ad_id.
Request Parameter - from - Start minute - long, to - End time - long, filter - Identifier for different filtering strategies. Example filter = 001 for non-US clicks - long.
Response - ad_id - The identifier of the ad - _String, count - The aggregated count between start and end time - long.
Return top N most clicked ad_ids in the last M minute.
GET /v1/ads/popular_ads Return top N most clicked ad in M minute.
Request parameter - count - Top N most clicked ads - int, window - The aggregatio window size(M) in minutes - int, filter - An identifier for different filtering strategies - long.
Response - ad_ids - A list of the most clicked ads - array
Data Model
There are 2 types of data - raw data and aggregated data.
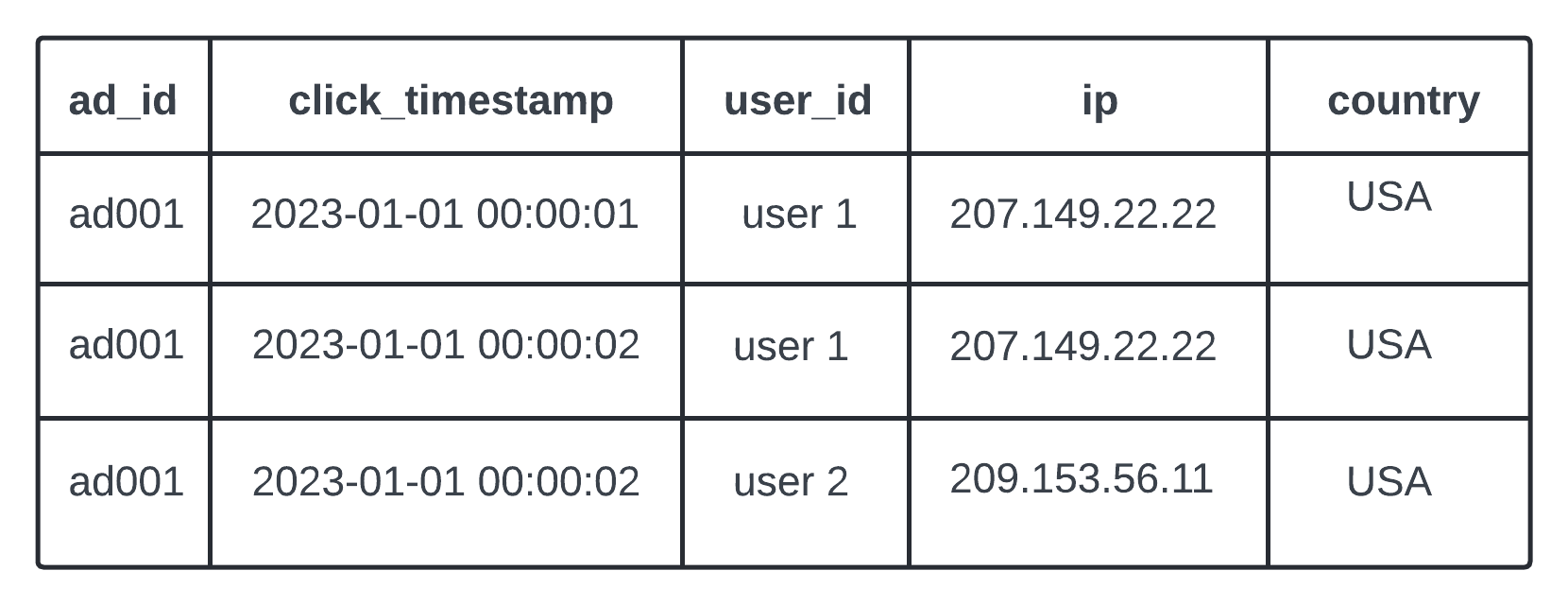
Raw Data - [AdClickEvent] - ad001, 2021-01-01 00:00:01, user 1, 207.149.22.22, USA
List of data fields in a structured way in different application servers.
Aggregated Data - Ad click events are aggregated in every minute. Filtering there is filter_id. Record with same ad_id and click_minute are grouped by filter_id.
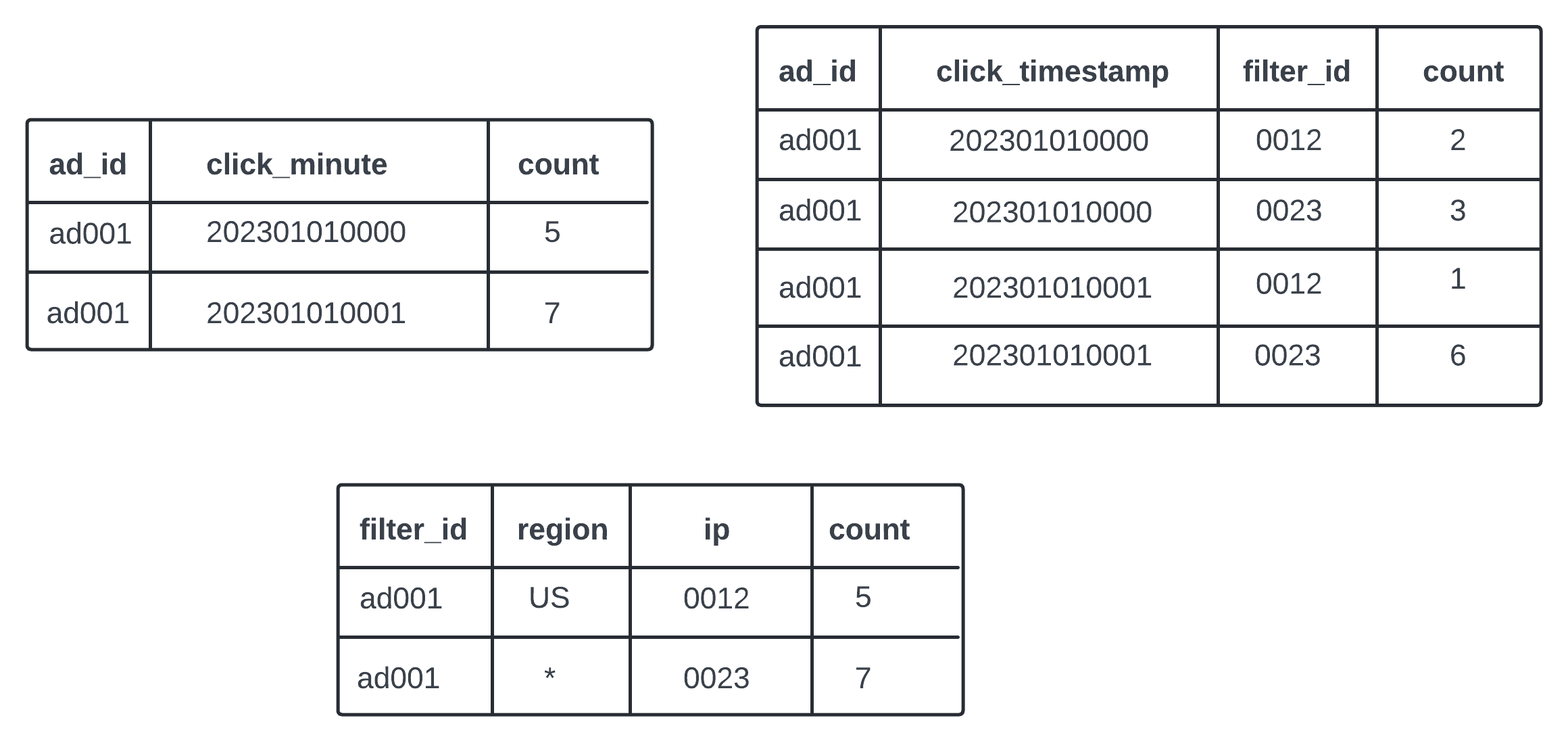
TODO
Comparison between storing raw data and aggregated data
Pros.
Raw Data - Full Data set. Support data filter and recalculations.
Aggregated Data - Smaller data set. Fast query.
Cons.
Raw Data - Huge data storage. Slow query.
Aggregated Data - Data loss. This is derived data. For example - 10 entries aggregated to 1 entry.
Which one to use?
Use both.
Good idea to keep raw data. Anything goes wrong, aggregated data corrupted due to bug then we can recalculate the raw data.
The data size of raw data is huge the query will be inefficient. To mitigate we need to run queries on aggregated data.
Raw data serves as backup we only query when recalculation needed and old data can be send to data storage to reduce cost. Aggregated data serves as an active data.
Choosing the right database.
To choose the right db we need to evaluate few things in every design.
What does the data look like? relational or document or blob?
Workflow read heavy or write heavy?
Transaction support needed?
Do the queries rely on many online analytical processing like SUM, COUNT?
Raw data - no need to query but useful for data engineer to study user response nad behaviour and feedback.
The average QPS is 10,000 the system is write heavy. The read side raw data is used as backup and source for recalculation the read volume is low. RDBMS can do the work. Scaling the write can be challenging. NoSQL like Cassandra and InfluxDB are more suitable as they are optimized for write and time-range queries.
Another option store in S3 using columnar data formats like ORC, Parquet, AVRO. Put a cap on the size of each file (10GB) and the stream processor responsible for writing the raw data could handle the file rotation when the size cap is reached. Not familier system.
Lets stick to Cassandra. Aggregated Data - Time-series in nature and the workflow is read and write heavy. In each ad we need to query the db every minute to display the latest aggregation count for customers. This feature is useful for auto-refreshing the dashboard or triggering alerts in a timely manner. There are 2 million ads in total the workflow is read heavy. Data aggregated and written every minute by the affrefation service so it is write heavy. We can use the same type if database to store both raw data and aggregated data.
General design structure - Query design and data model and then the high level design.
High Level Design.
In big data processing, the data flows in and out as unbounded data streams. The aggregation service works in the same wat - input is raw data (unbounded data stream) and the output is the aggregated result.
Asynchronous Processing.
The design is synchronous - The capacity of the producer and consumer is not same when the increase in event then the consumer will give out-of-memory error or stop. One component in synchronous is down then the whole system stops working.
The most common solution to use the Kafka to decouple the producer and consumers. The process is asynchronous and the producer and consumer can be scaled independently.
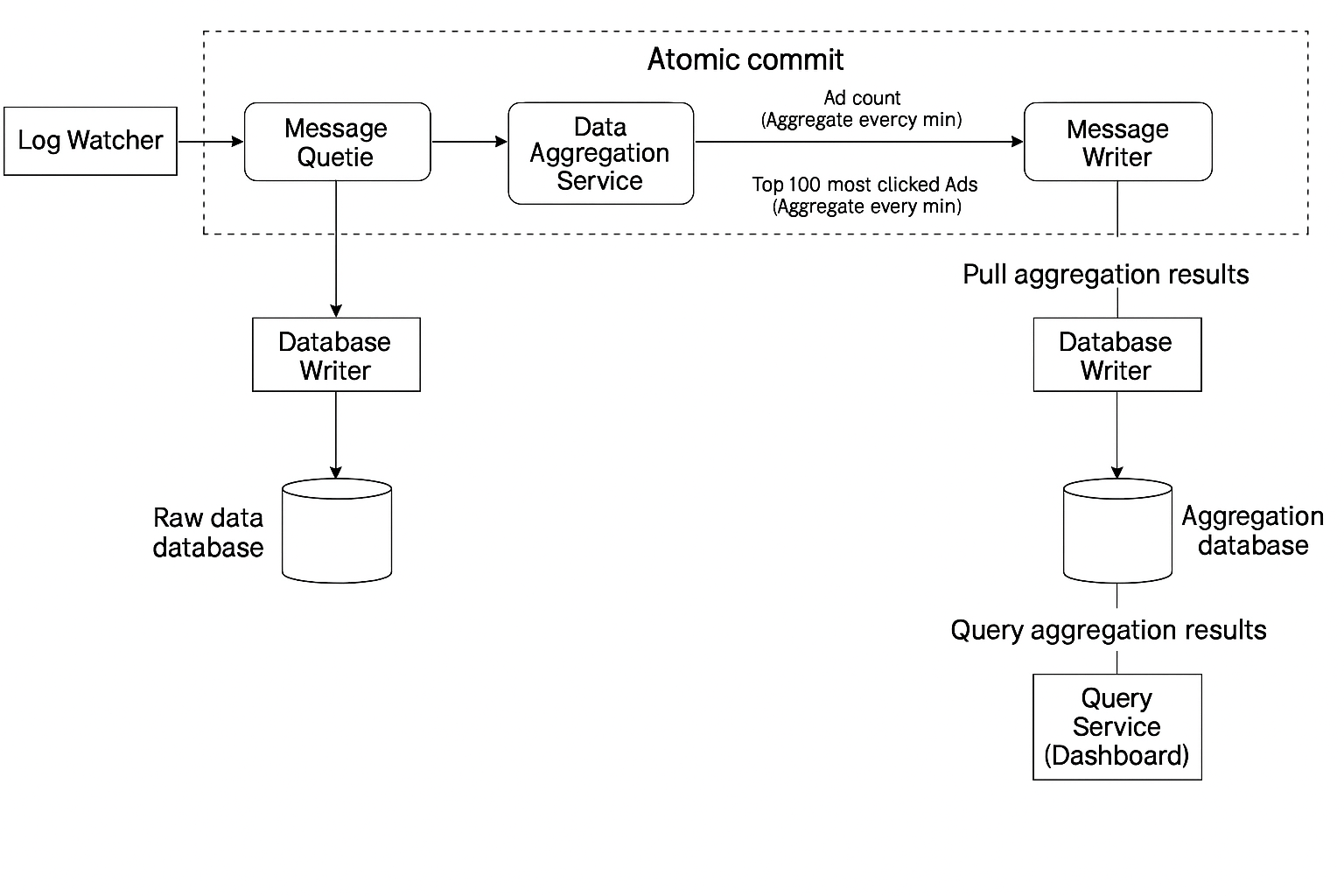
In the design the log watcher, aggregation service and database are decoupled by 2 message queue. The database writer polls data from the message queue, transform the data into teh database format and write to the database.
First message queue - contains ad click event data - ad_id, click_timestamp, user_id, ip, country.
Second message queue - contains 2 types of data.
Ad click aggregated at per-minute - ad_id, click_minute, count.
Top N most clicked ads aggregated at per-minute - update_time_minute, most_clicked_ads.
Aggregation Service.
The MapReduce framework is a good option to aggregate ad click events. The DAG is a good model. The key to the DAG is to break down the system into small computing units like Map/Aggregate/Reduce nodes.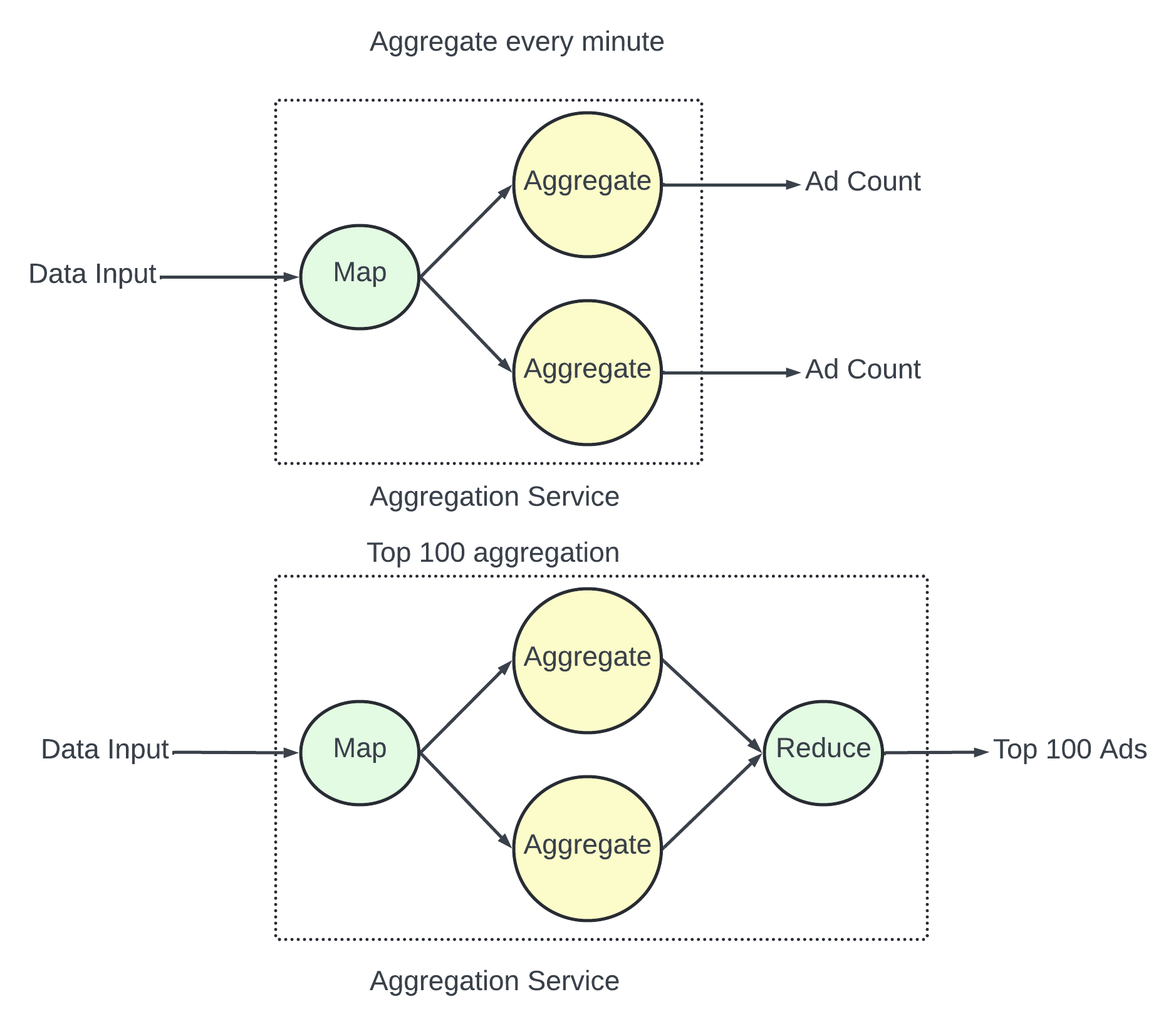
Map Node.
A Map node reads data from the data source and then filters and transforms the data. A mapndoe sends ads with ad_id%2=0 to node 1 and the other ads go to node 2.
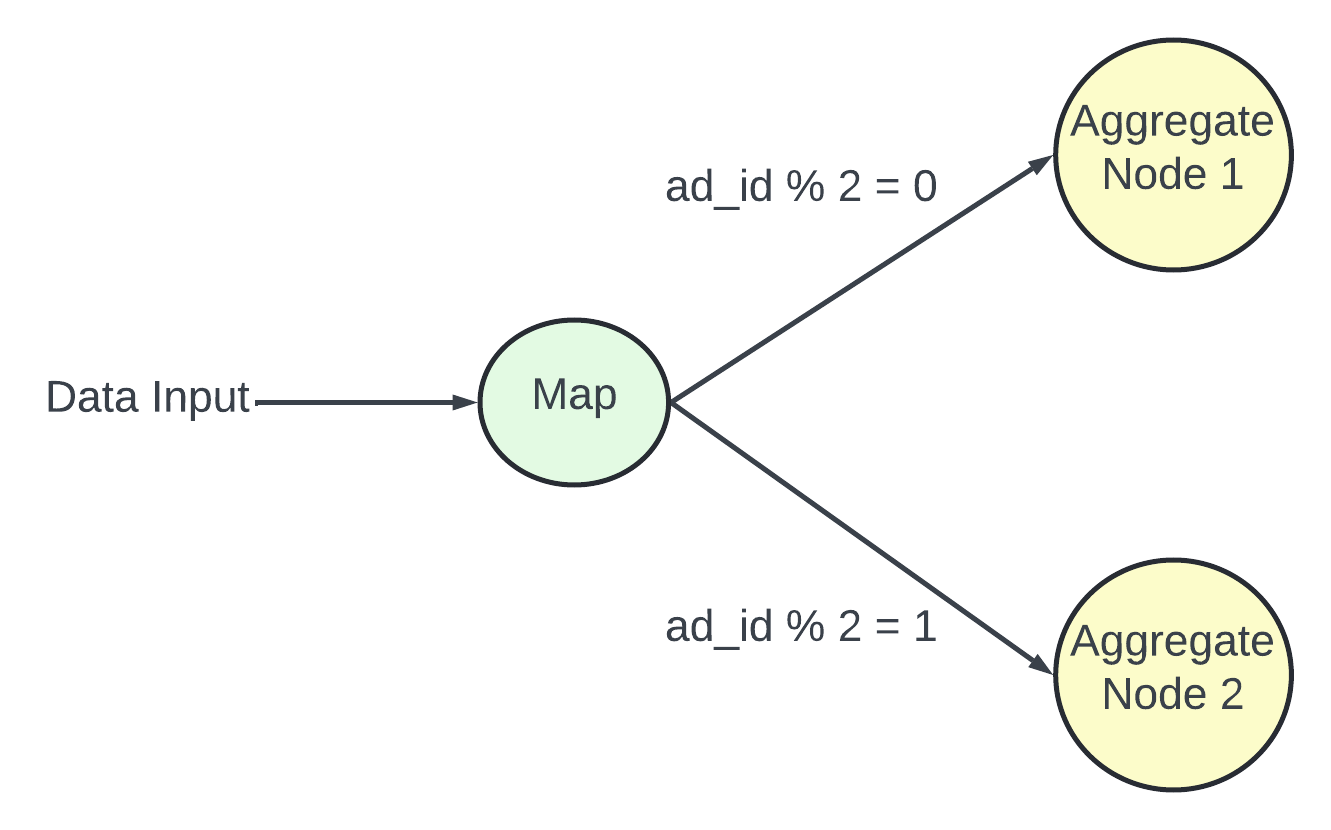
Counter - Why to use Map node. We can set up Kafka partitions or tags and let the aggregate nodes subscribe to Kafka directly. It work but the input data may need to be cleaned or normalized and these operations can be done by the Map node. Another reason the control over how data is producer is not possible and the events with the same ad_id might land in different Kafka partitions.
Aggregate Node.
An aggreagate node counts ad click events by ad_id in memory every minute. In the MapReduce paradign, the Aggreagte node is part of the reduce. So the map-aggregate-reduce means map-reduce-reduce.
Reduce Node.
A reduce node reduces aggregated result from all “Aggregate” nodes to the final result. There are 3 aggregation nodes and each contain top 3 most clicked ads within the node. The reduce node reduces the total number of most clicked ads to 3.
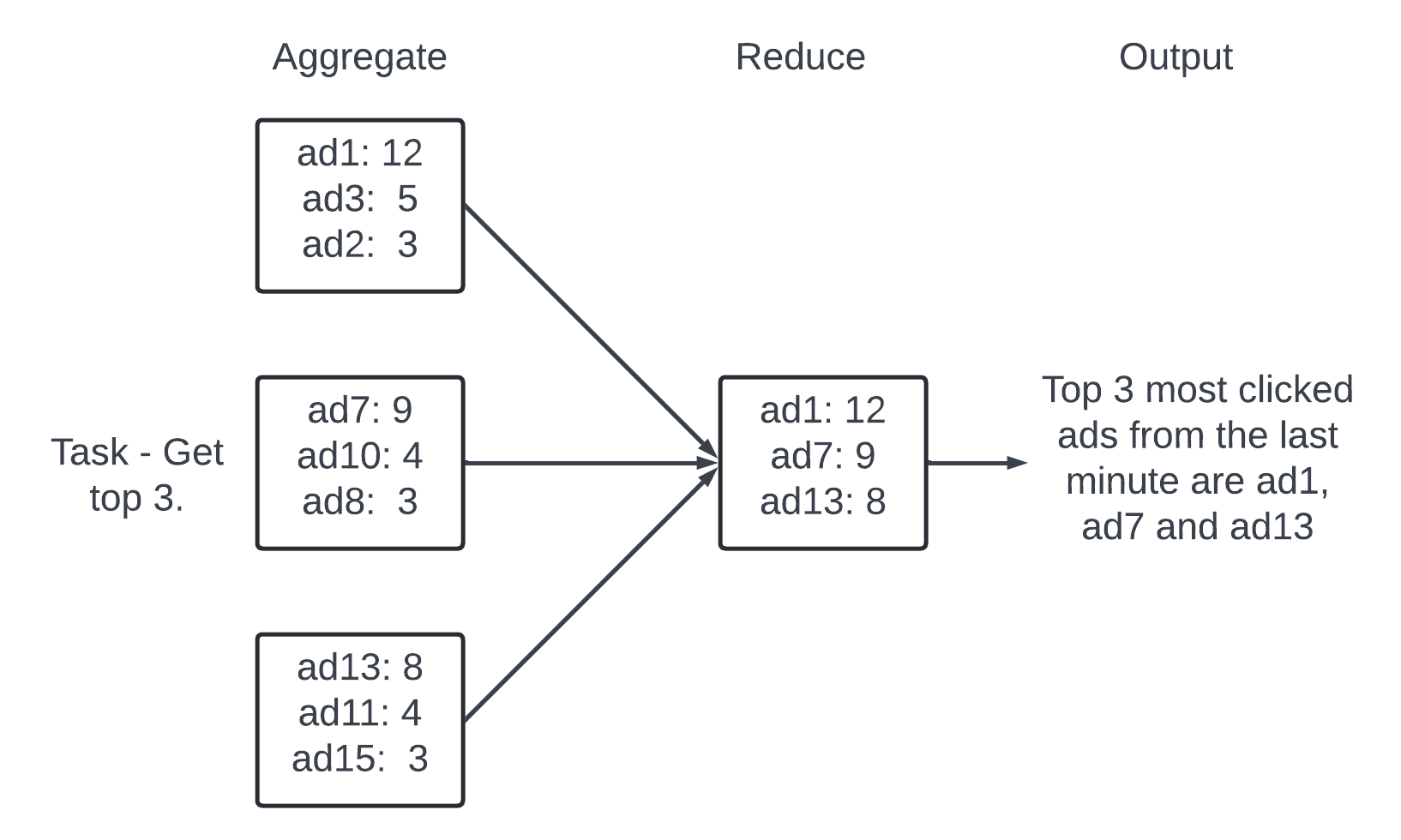
The DAG model represents the MapReduce pradigm. It is designed to take big data and use parallel distributed computing to turn big data to small size data.
In the DAG model intermediate data can be stored in memory and different nodes communicate with each other through TCP(node running in different processes) or shared memory(node runing in different threads).
Map Reduce use case - Aggregate the number of clicks.
Input events are prtitioned by ad_id (ad_id%3) in Map node and are then aggregated by the Aggregation node.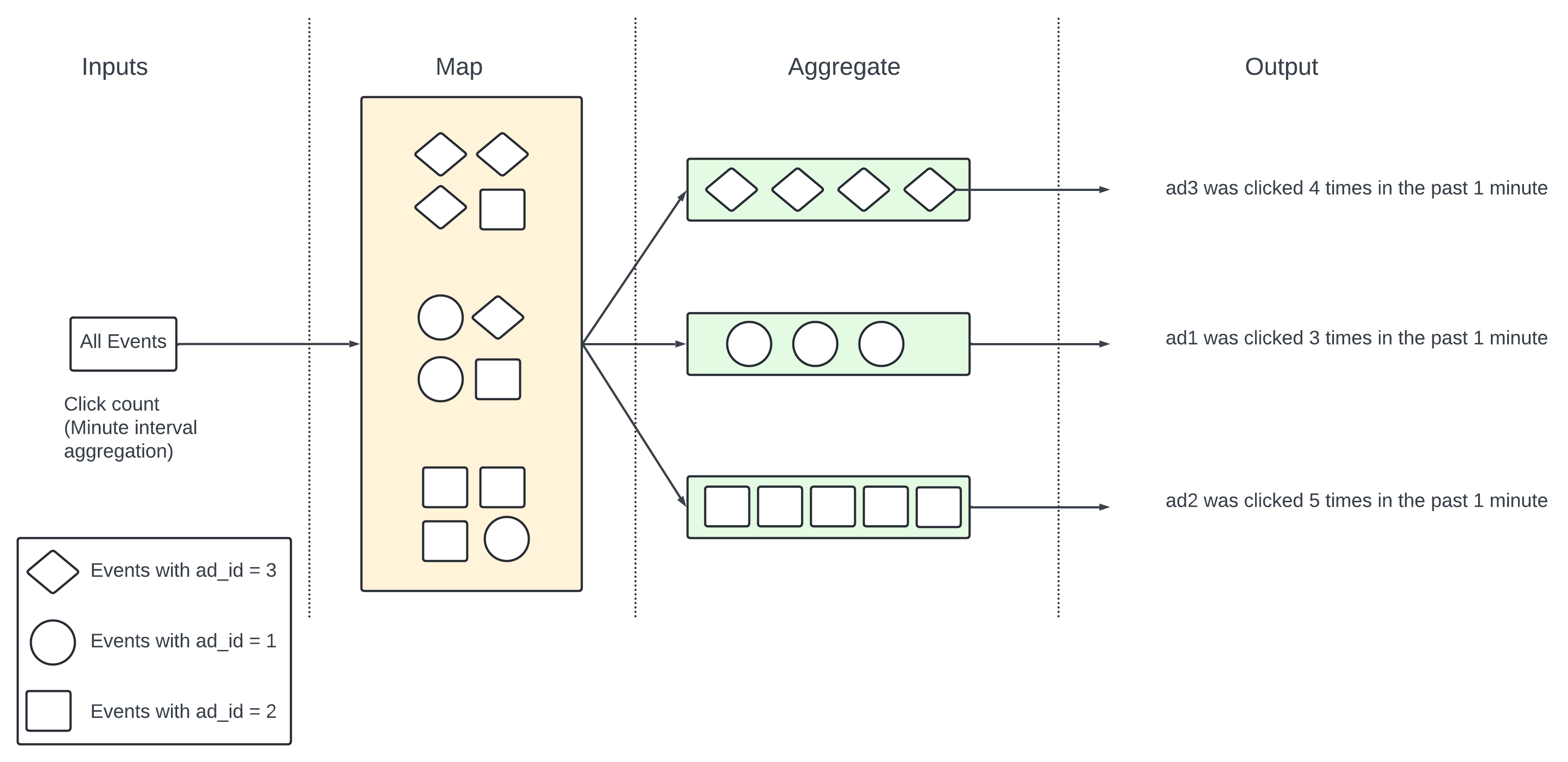
Input events are mapped using ad_id and each aggregate node maintains a heap data structure to get the top 3 ads within the node. In the last the Reduce node give the top 3 most clicked ads every minute.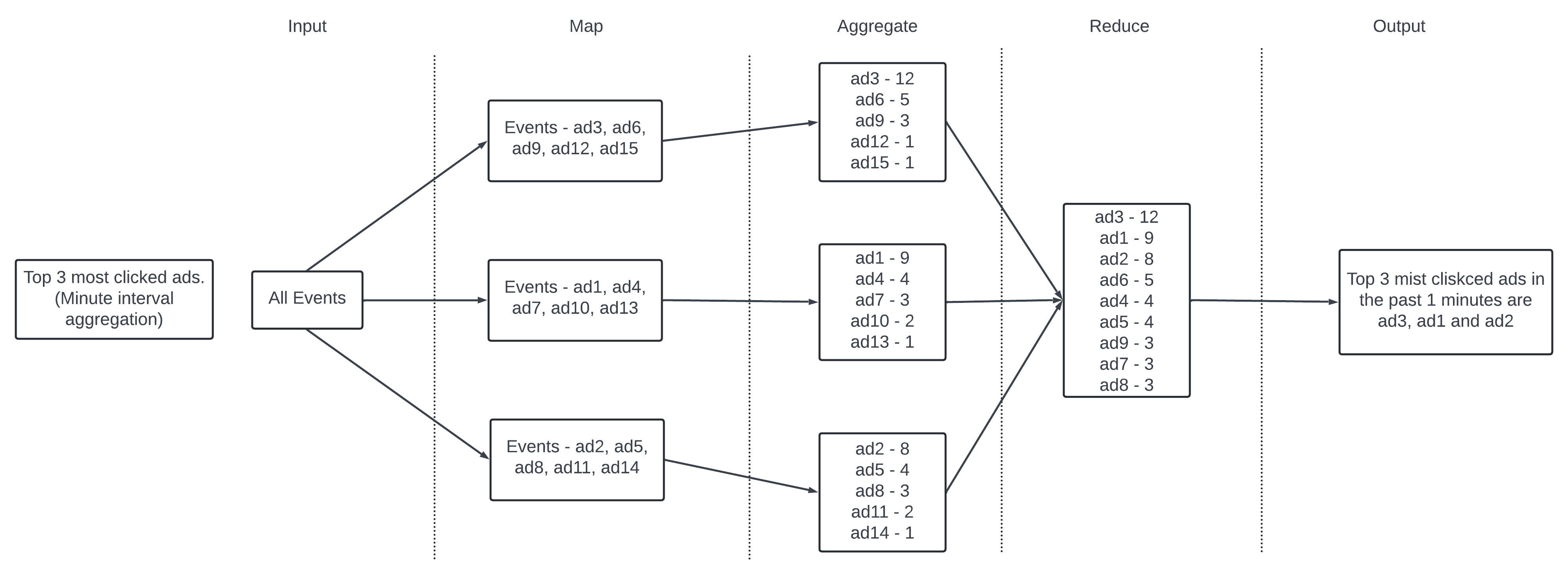
Data Filtering like - “Show me the aggregated click count for ad001 within USA only” - pre-define filtering criteria and aggregate based on them.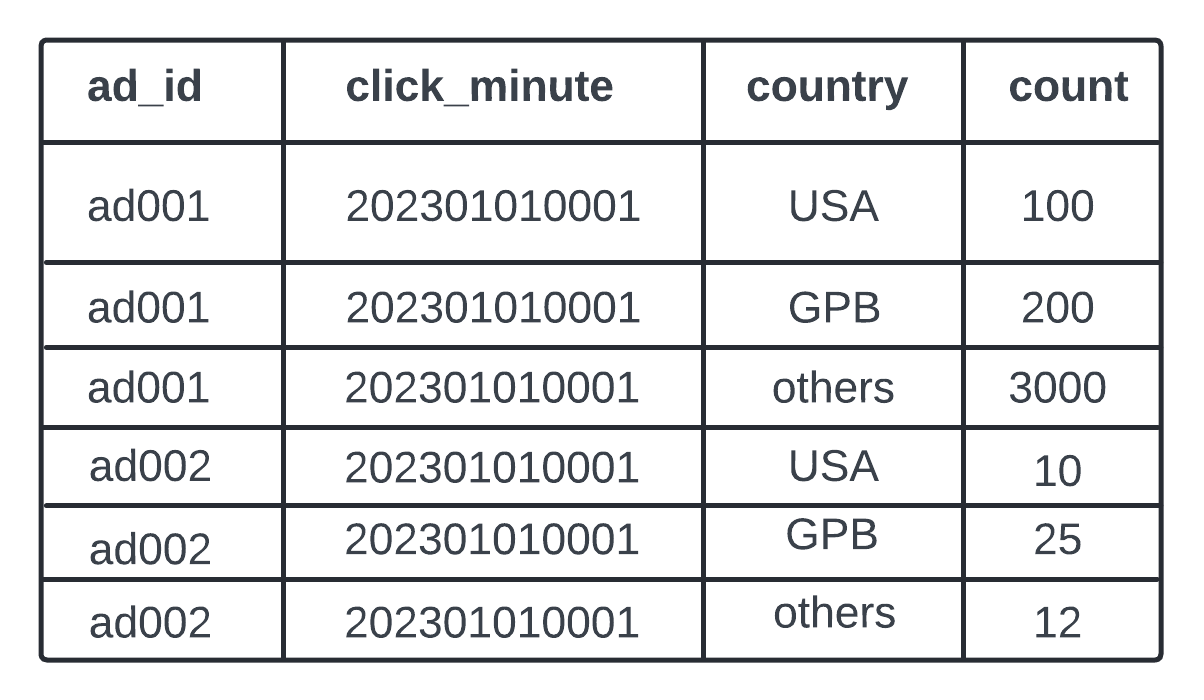
The current aggregation service can be reused to create more dimensions in the star schema. No additional component is needed.
Accessing data based on filtering criteria is fast as the result is pre-calculated.
The limitation it will cerate more buskets and records when we have lot of filtering criteria.
Design Deep Dive.
Deep dive in the following - Streaming vs Batching, Time and aggregation window, Delivery guarantees, Scale the system, Data monitoring and correctness, Final design, Fault Tolerant.
Streaming vs Batching. The high level design is based on the stream processing. Comparison between the system.
| Services(Online System) | Batch System(Offline System) | Streaming System(Near Real-Time System) |
|---|---|---|
| Response to client quickly. | No response to the client needed. | No response to the client needed. |
| Input is user request. | Bounded input with large amount of data. | Input has no boundary infinite stream. |
| In output gives response to the client. | In output gives materialized views, aggregated metrics. | In output gives materialized views, aggregated metrics. |
| Performance - availability, latency. | Performance - Throughput. | Performance - Throughput, latency. |
| Example - Online Shopping. | Example - MapReduce. | Example - Flink. |
In the design both stream and batch processing are used.
Stream processing to process the data as it arrives and generates the aggregated results in near real time. Batch processing for processing the data backup.
System containing batch and stream simultaenously - the architecture called lambda. Cons - 2 processing path meaning two codebase to maintain.
Kappa architecture combines the batch and streaming in one processing path solves the problem. The key is to handle both real-time data processing and continuous data reprocessing with a single stream processing engine.
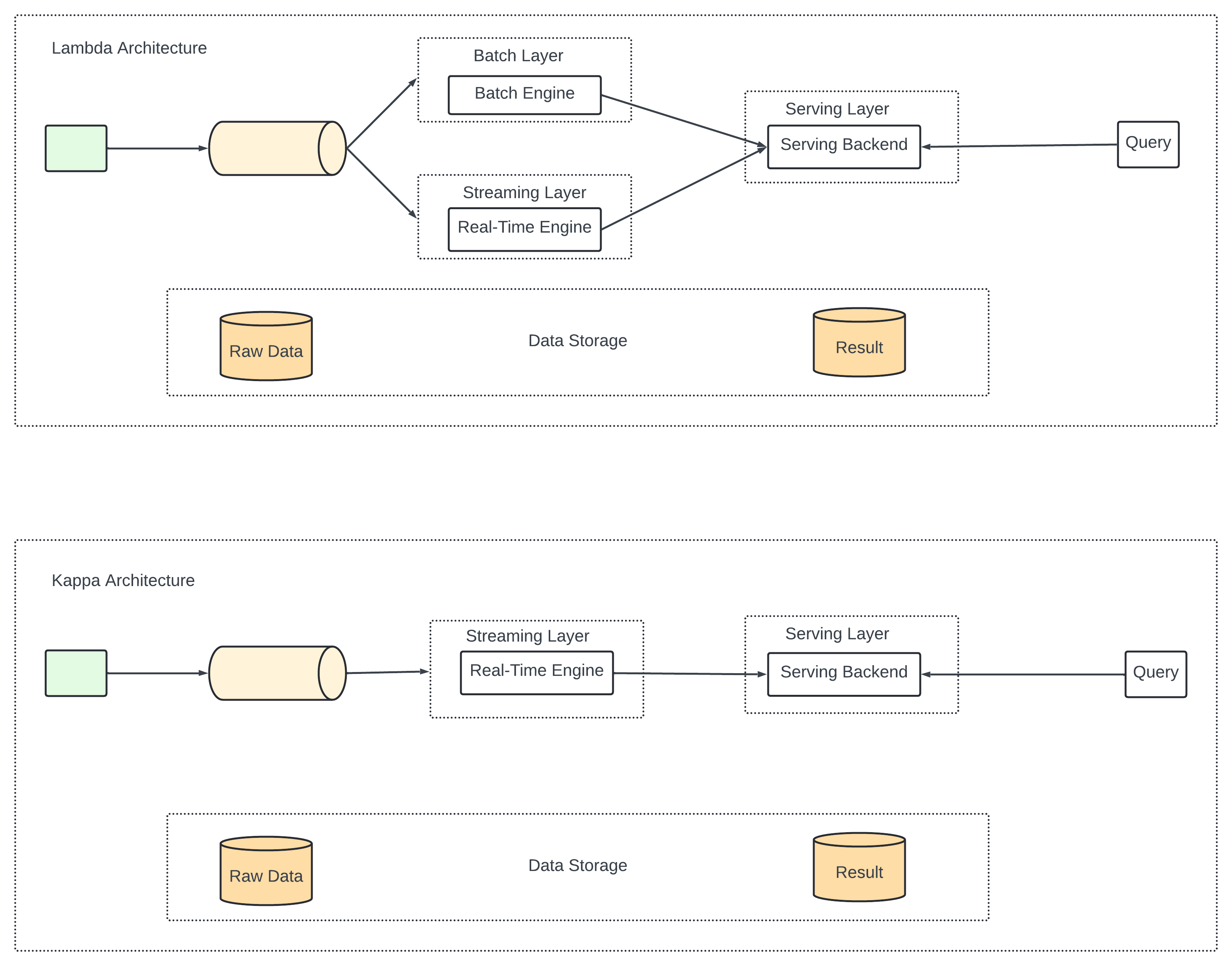
Data Recalculation.
There are times when we have to recalculate the aggregated data - historical data replay - any errr in the aggregation service we need to recalculate the aggregated data from the raw data to solve the error.
The flow of the data recalculation -
The recalculation service retrieves data from the raw data storage - batched job.
Retrieved data sent to a dedicated aggregated service so no real time data impacted by historical data.
Aggregated results are sent to the second message queue - then updated in the aggregation database.
The recalculation process reuses the data aggregation service but different data source.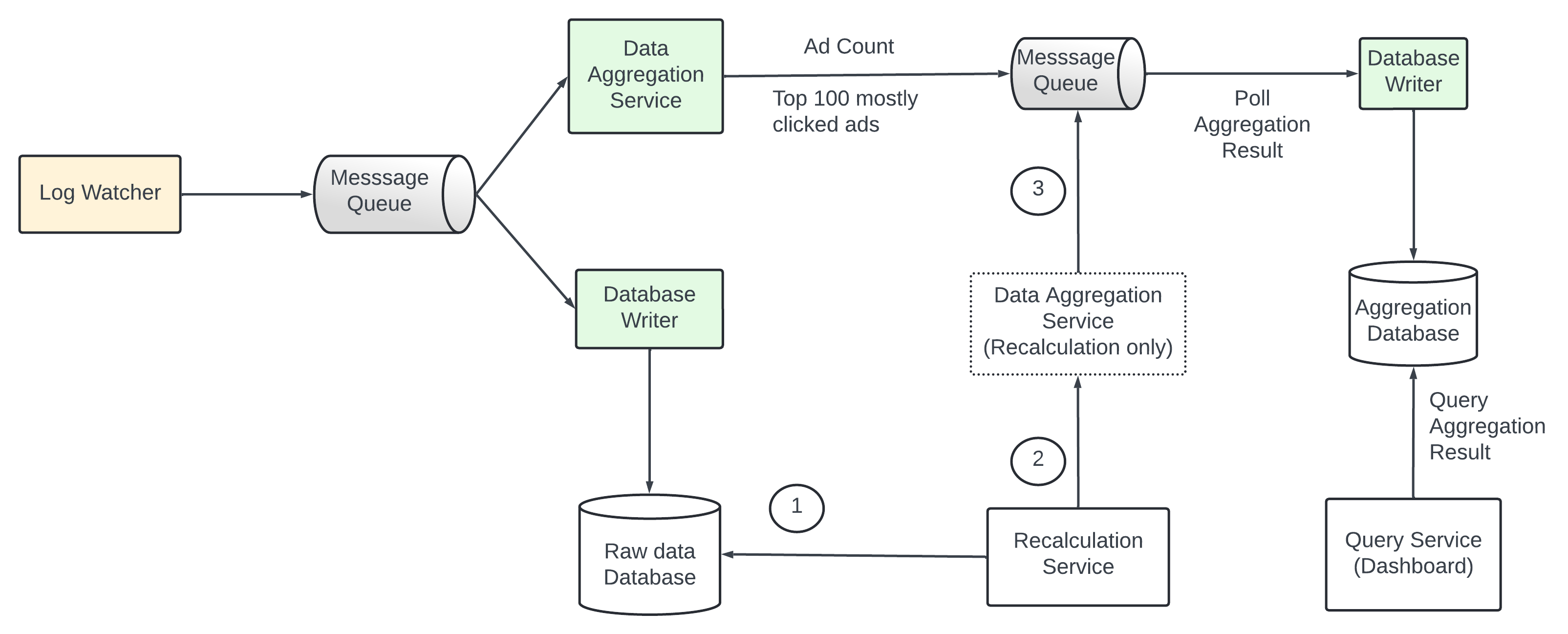
Time.
Timestamp to perform aggregation - It can be generated in 2 different places - Event Time - When an ad click happens and Processing Time - the system time of the aggregation server that processes the click event.
The gap between the event time and processing time can be large - event arrive in the aggregation service after 5 hour.
Using the event time in the aggregation then need to deal with delay and processing time used then the result is not accurate. Need to decide the tradeoff.
Event Time in Aggregation Service - Pros - Aggregation results are more accurate because the client knows exactly when an ad is clicked.
Cons - Depends on the timestamp on the client side.
Processing Time in Aggregation Service - Pros - Server timestamp is more reliable.
Cons - The timestamp is not accurate if an event reaches the system at a much later time.
Data accuracy go with Event time - Next up How do we properly process deplayed events in the case? - Watermark is commonly utilized to handle delayed events.
Ad event are aggregated in one-minute tumbling window - window 1 misses event 2, window 3 misses event 5 - event arrive later the end of the aggregation window.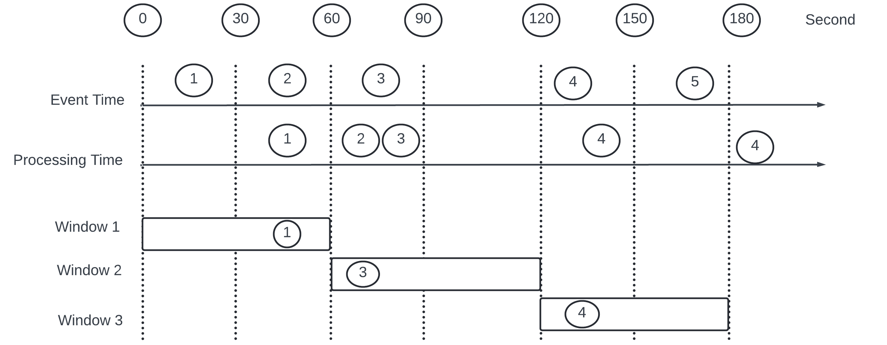
One way to solve it using Watermark - a extension as an aggregation window. Example - extending an extra 15 sec window 1 will be able to include event 2, window 3 can include event 5.
A long watermark could catch events that arrive very late but it will add latency. A short - means data is less accurate - add less latency to the system.
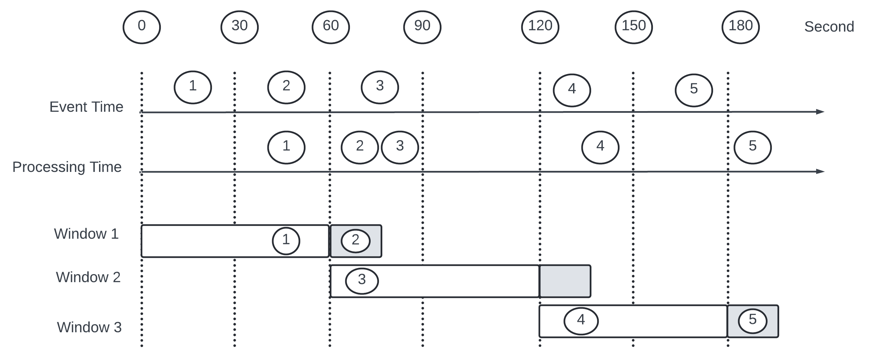
It does not handle event with long delay - not imp to make system more complicated - We can correct the tiny bit of inaccuracy with end-of-day reconciliation. One trade-off watermark improve data accuracy but increases latency.
Aggregation Window. Mainly 4 types of window function - tumbling window(fixed window), hopping window, sliding window, session window.
Tumbling Window.
Time is divided into same - length, non overlapping part. Good fit for aggregating ad click every minute.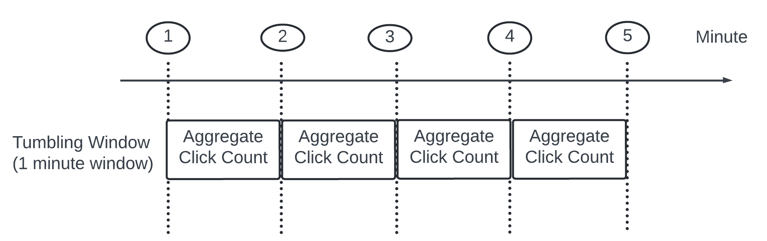
Event are grouped within a window that slides accross data stream - Can be over lapping - Good to get the top N most clicked ads during the last M minutes.
Delivery Guarantees.
Aggregation result is used in billing - Data accuracy and completeness are imp.
System needs to answer - How to avoid processing duplicate events?
How to ensure all events are processed?
Kafka provides 3 delivery semantics - at-most once, at-least once, exactly once.
At-least once is good (in place little duplicate are acceptable).
Here duplicate are not acceptable - Exactly-once in this design.
Data Deduplication One data quality issue - duplicate data. It can come from wide range of source - Client side and Server Outage.
Client side - Client send same event multiple time. Malicious intent can be handled by fraud and risk control.
Server outage - When aggregation service node goes down in the middle of aggregation and the upstream service has not received an ack the same event might be sent and aggregate again.
The diagram show the aggregation service node outage introduces duplicate data. The Aggregator manages the status of data consumption by storing the offset in upstream Kafka.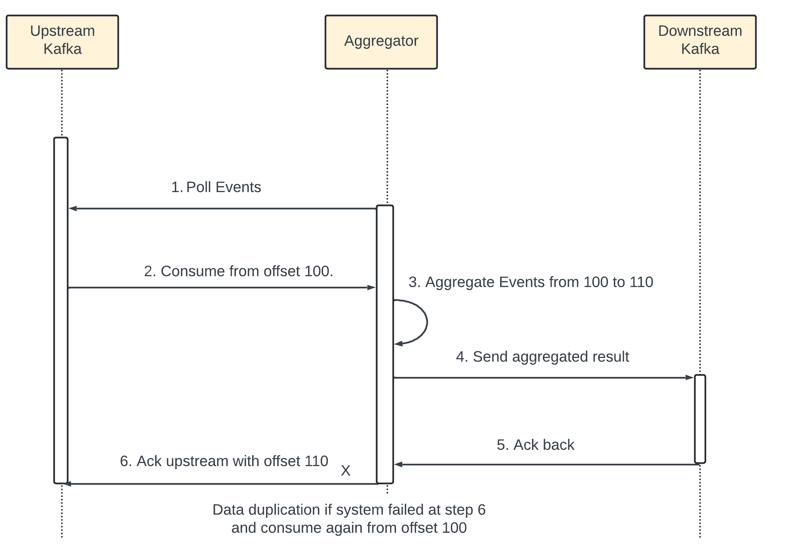
Step 6 failsdue to outage - event from 100 to 110 are sent to downstream but the new offset 110 is not persisted in upstream Kafka.
Now the new aggregator would consume again from offset 100 - even if those are already processed - duplicate data.
Solution - Use an external file storage - HDFS or S3 to record the offset.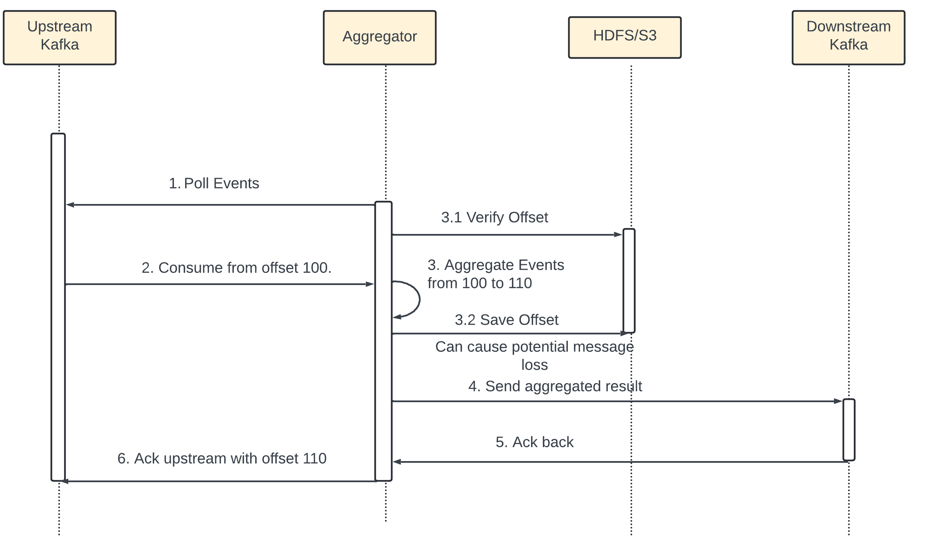
Issue - the offset is saved in S3 (step 3.2) before the result sent downstream. Step 4 fails due to outage then events from 100 to 110 will never be processed by newly brought up aggregator node as the offset stored in the storage is 110.
To mitigate this we need to save the offset after we get the ack from the downstream.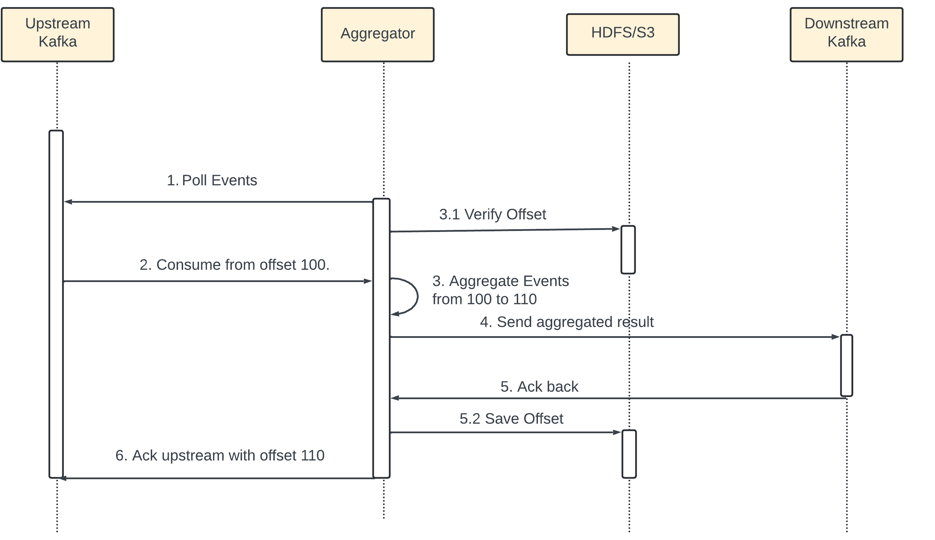
Distributed transaction works cross several nodes - any oeration fails the whole transaction is rolled back.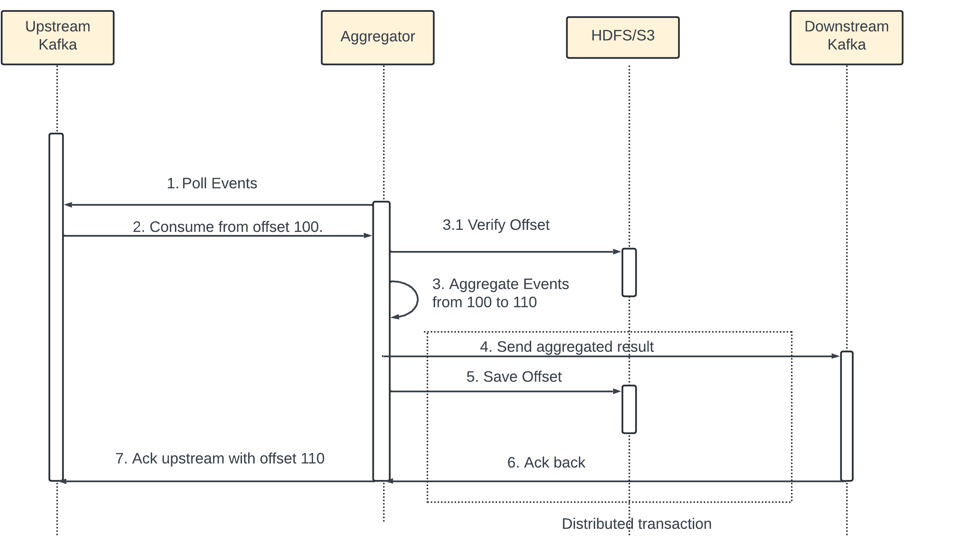
How to achieve exactly-once proessing is an advanced topic.
Scale the system. The estimation - business grow 30% per year - which double traffic every 3 years.
The system contains 3 independent component - message queue, aggregation service, database.
Scaling message queue (Scaling Distributed message queue part).
Producer - no limit - can increase in huge scale.
Consumer - Inside consumer group the rebalancing mechanish helps to scle the consumers by adding or removing nodes. Adding 2 or more consumers each consumer only processes events from one partition.
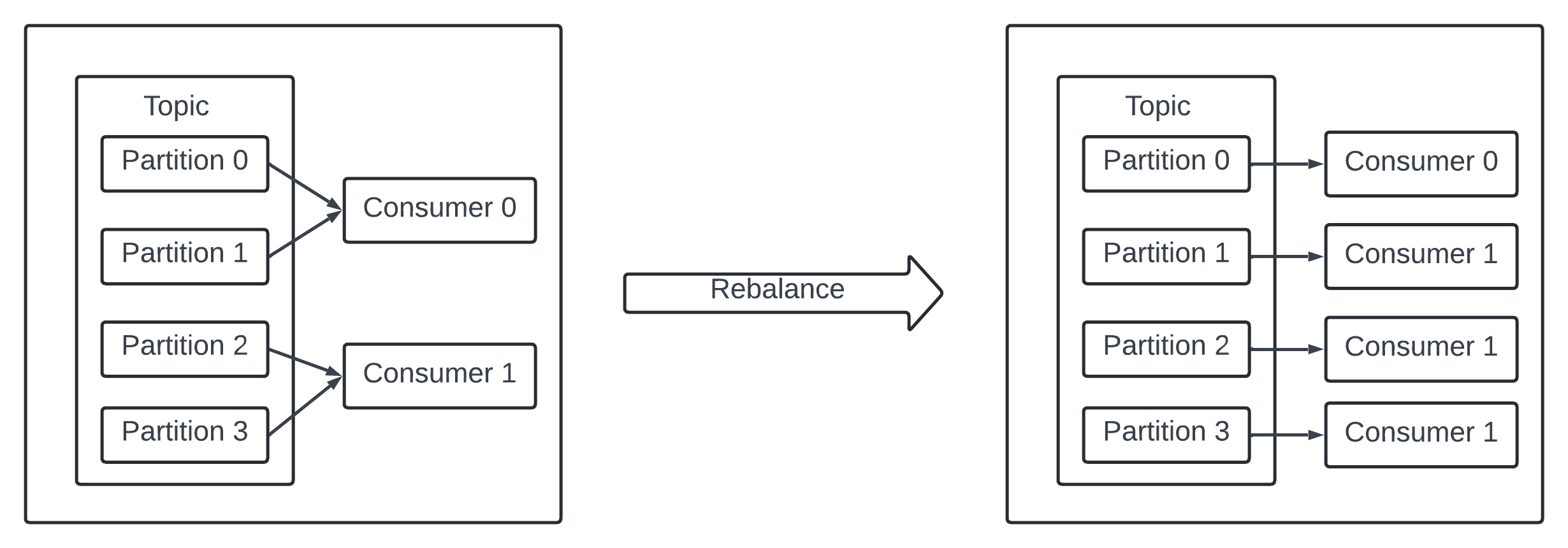
When there are many consumer then rebalance can take time - more consumer needs to add then add during off-peak hours to minimize impact.
Broker - Hashing Key - ad_id as hashing key for Kafka partition to store events from the same ad_id in the same partition. The aggregation service can subcribe to all events of the same ad_id from one single partition.
The number of partition - In case there is change in number of partition the same ad_id wil be mapped to different partition - Good to pre-allocate enough partition in advance to avoid dynamically increasing the number of partition.
Topic physical sharing - One topic not enough - split by location(topic_north_america, topic_europe) or business type (topic_web, topic_mobile). Pros - Slicing data in topic increase the system throughput. Less consumers for a single topic the time to rebalance consumer groups is reduced. Cons - Complex and maintenance costs.
Scaling Aggregation Service.
Aggregation service has a map/reduce operation. It is horizontally scalable by adding or removing nodes.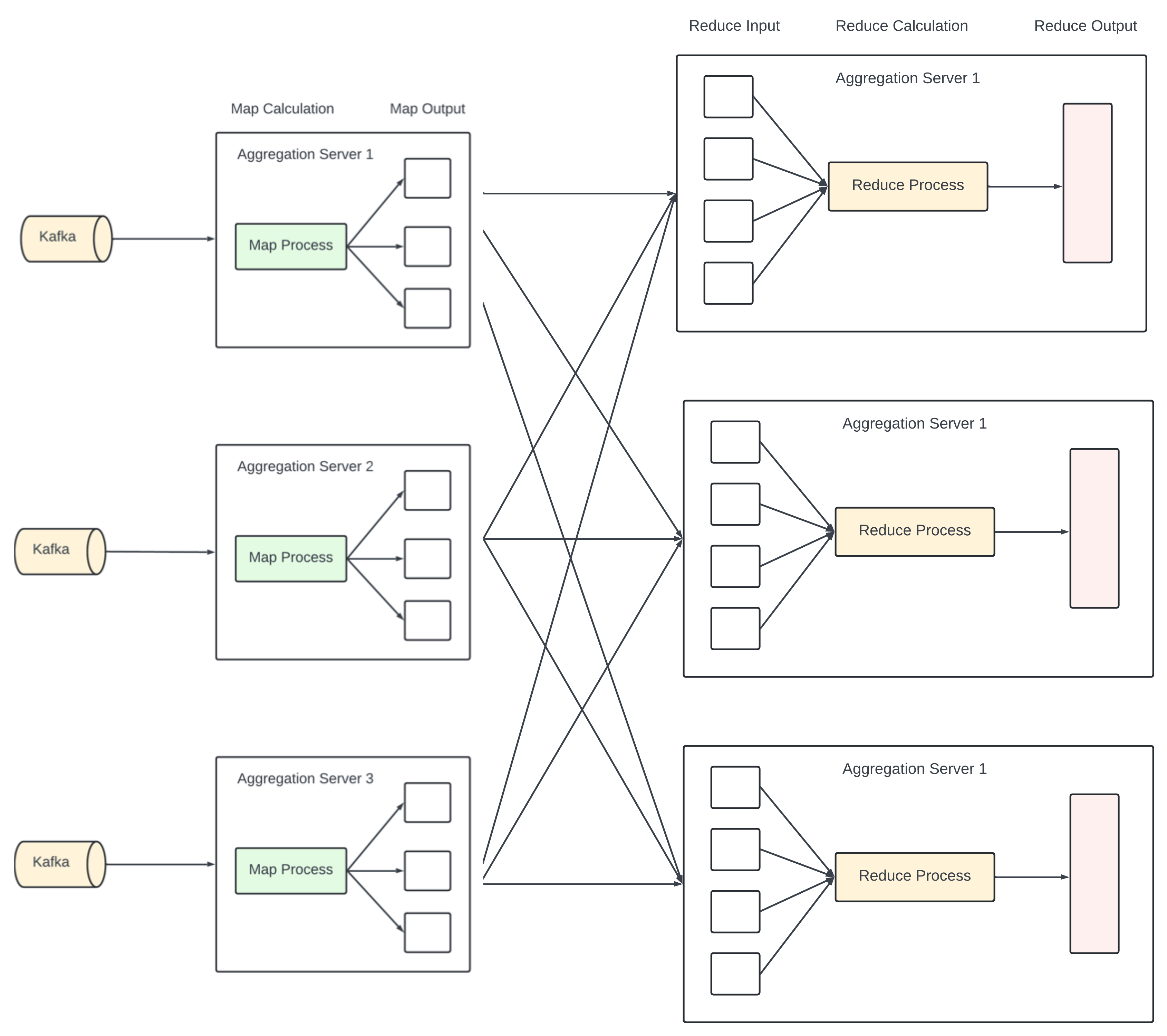
How do we increase the throughput of the aggregation service?
Option 1 - Allocate events with different ad_ids to different threads.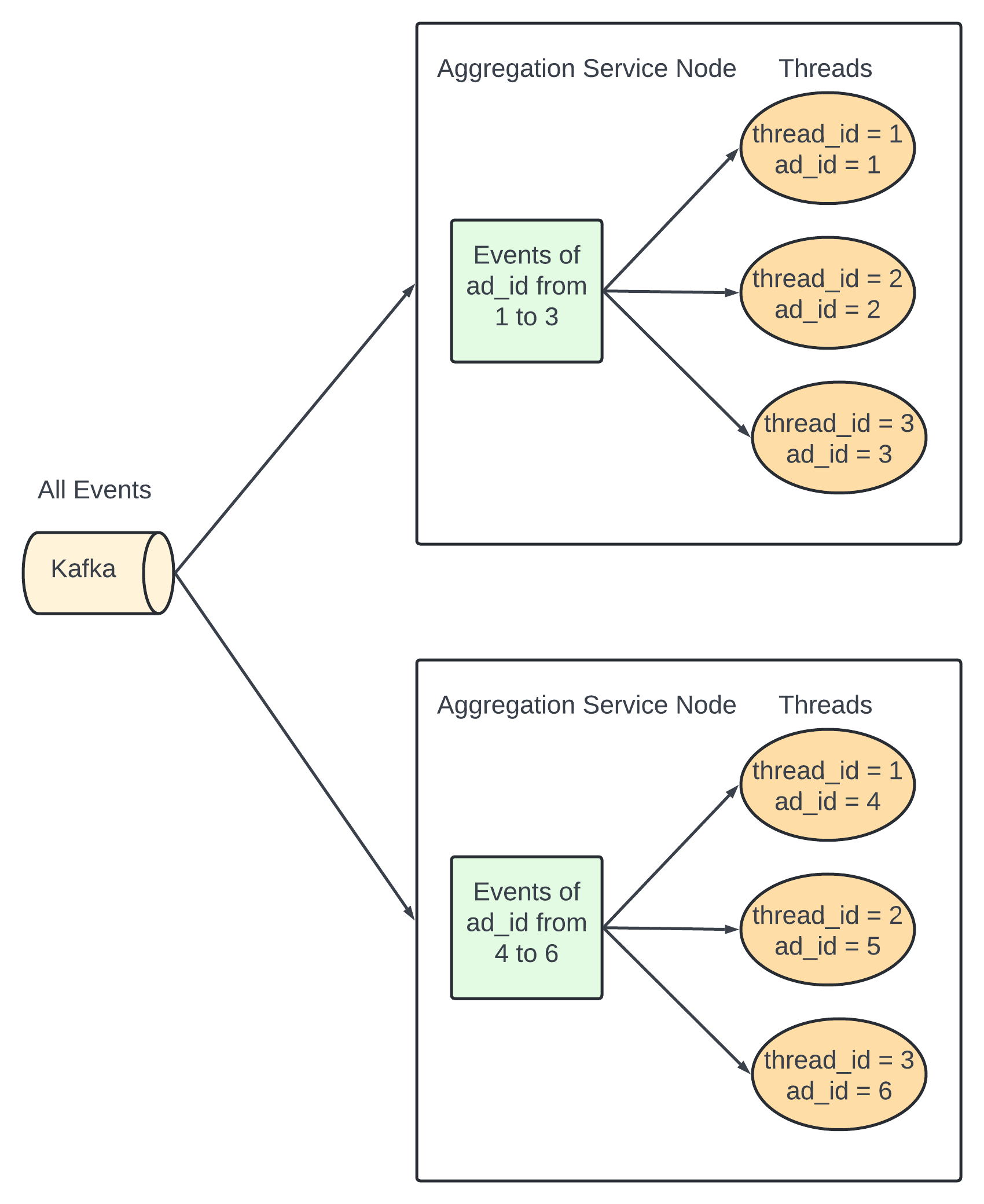
Scale the database
Cassandra supports horizontal scaling - like consistent hashing. Data is evenly distributed to every node with proper replication factor.
Each node save own part based on hashed value and ls saves copies from other virtual node.
Adding new node to the cluster it automatically rebalances the virtual nodes among all nodes. No manual resharding is required.
Hotspot Issue A shard or service that receives much more data than the others called hotspot.
Many companies with more budget give more ad and are clicked more often. Events are partitioned by ad_id - some aggregation service nore might receive more ad clicks than others causing overload. Solution - more node to process popular ad.
Example - Each node can handle 100 events. There are 300 events in the aggregation node - it applies for more resources through resource manager.
Resource manager give more resourec adding 2 node to avoid overload. The original node splits the evenst in 3 groups and each node handles 100 events. The result is written back to the original node.
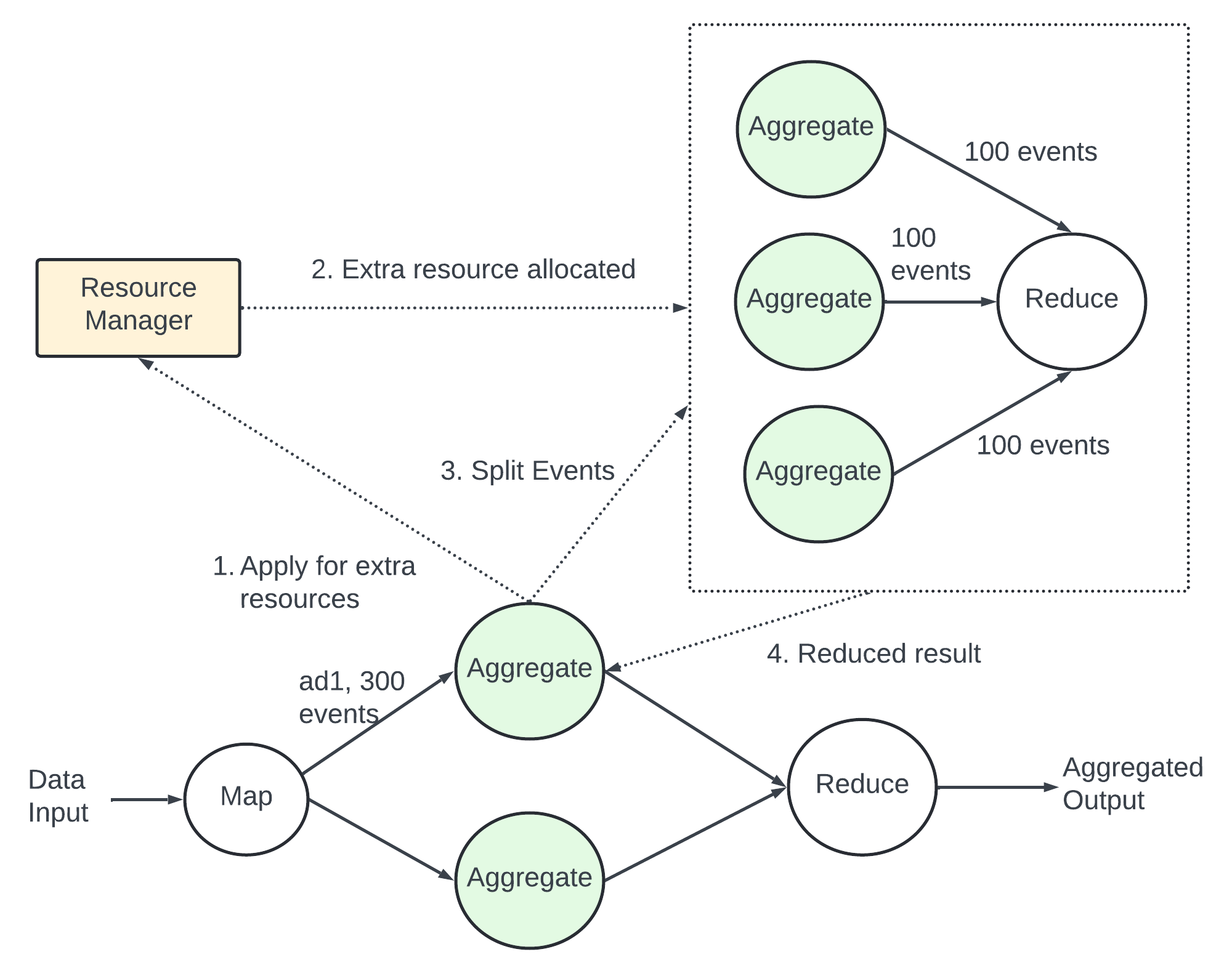
The other way to handle hthe problem - Global Local Aggregation or Split Distinct Aggregation.
Fault Tolerance.
Aggregation happens in memory - when an aggregation node goes down the result are lost. We can rebuild the count by replaying events from upstream Kafka brokers.
Replaying data from the beginning in Kafka is slow. A good practice is to dave the “system status” like upstream offset to a snapshot and recover from the last saved status. It is doing more like store the data like top N most clicked ad in the past M minutes.
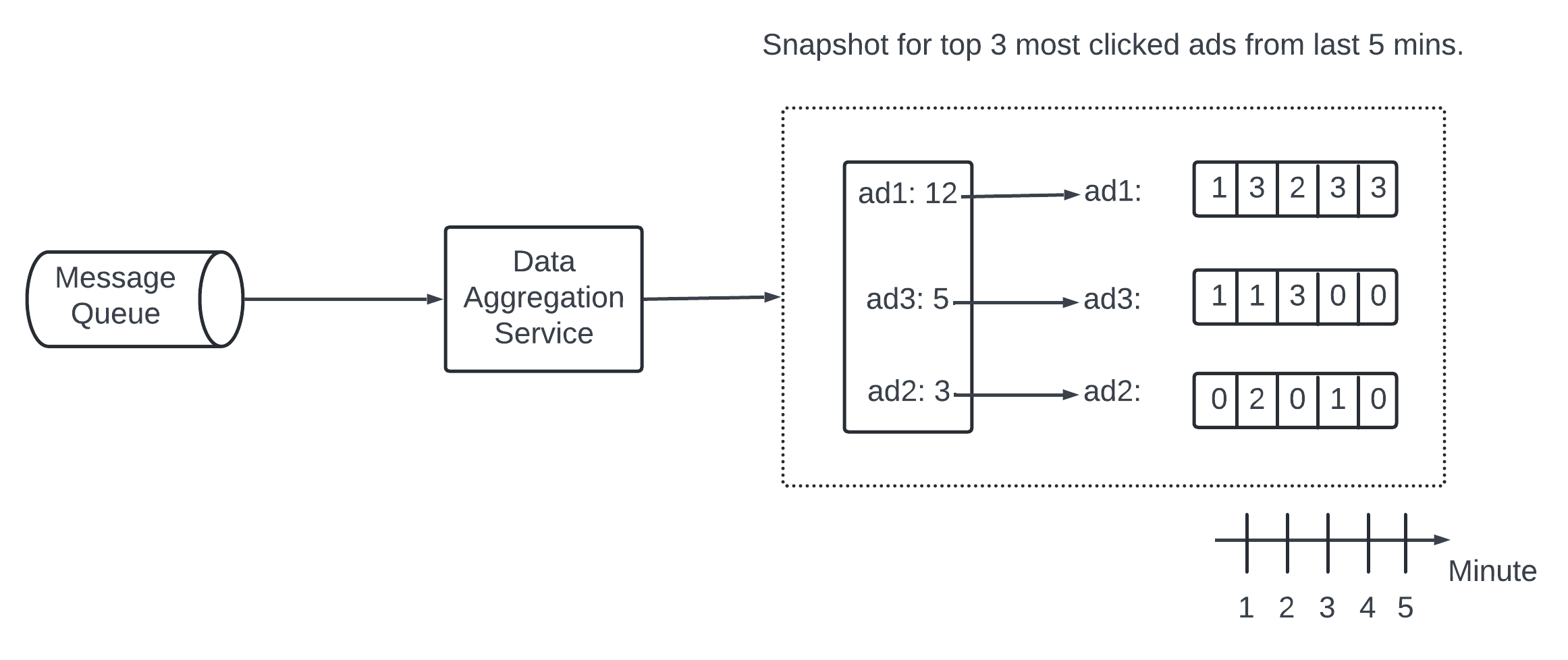
With the snapshot the failover process of the aggregation service is quite simple. One fail - bring new node and recover data from the latest snapshot. New events that arrive after the last snapshot was taken - the new aggregation node will pull those data from the Kafka broker for replay.
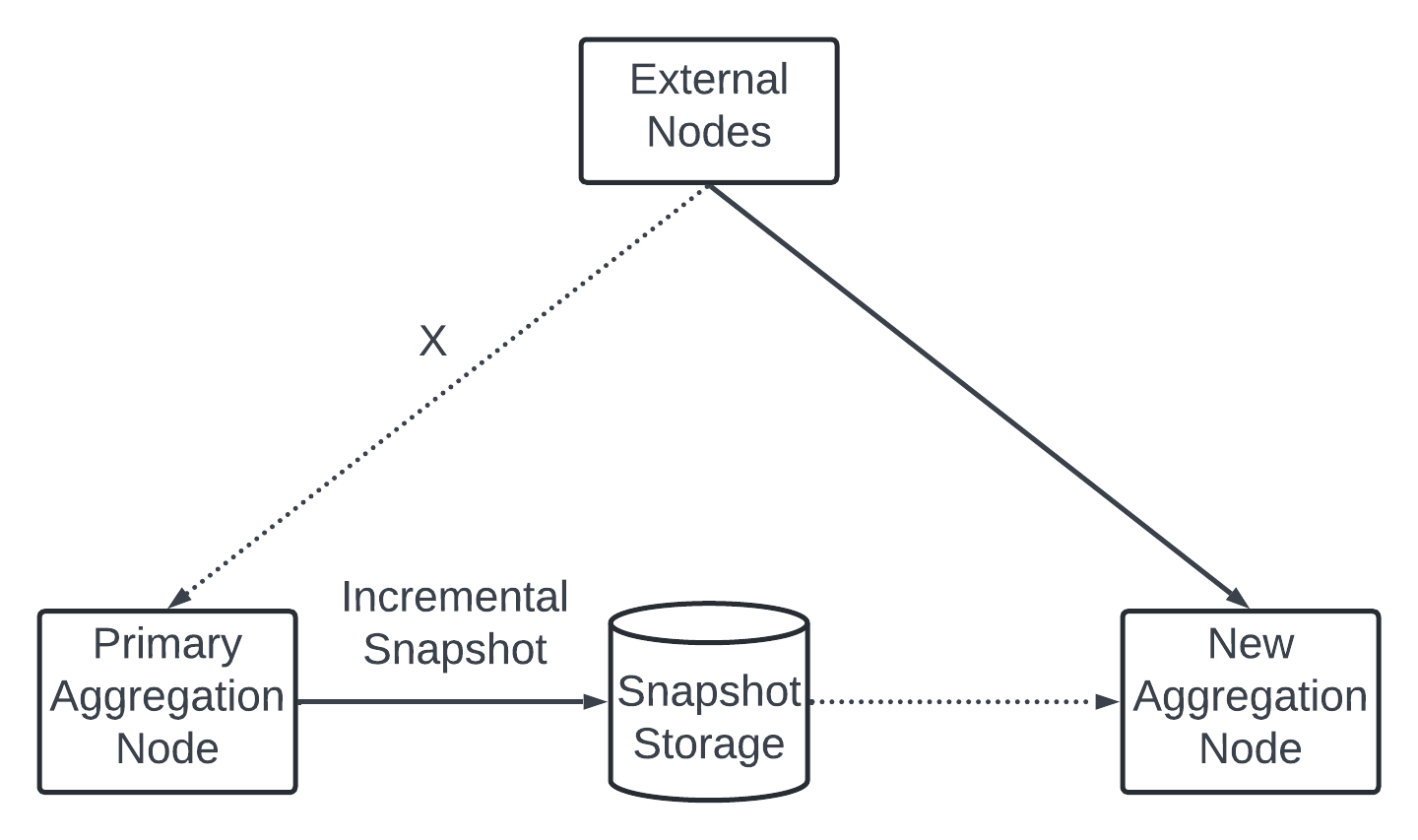
Data Monitoring and Correctness. Metrics we need to monitor - Latency, Message queue size, System resources on aggregation nodes like CPU, disk, JVM.
Latency - Track timestamp as events flow through different parts of the system. The differences between those timestamps can be exposed as a latency metrics.
Message queue - Increase in queue size we need to add more aggregation node. Kafka is a distributed commit log so we need to monitor the records-lag metrics.
Reconciliation.
Reconciliation - comparing different sets of data in order to ensure data integrity.
Unlike in bank industry we compare your record with the banks record - the result of ad click aggregation has no third party result to reconcile with.
We can sort the ad click events by the event time in every partition at the end of the day using batch job and reconciling with the real time aggregation result.
More accuracy - smaller aggregation window - 1 hour.
There will be always some difference in the data in the batch job and real streaming job as some event will come later.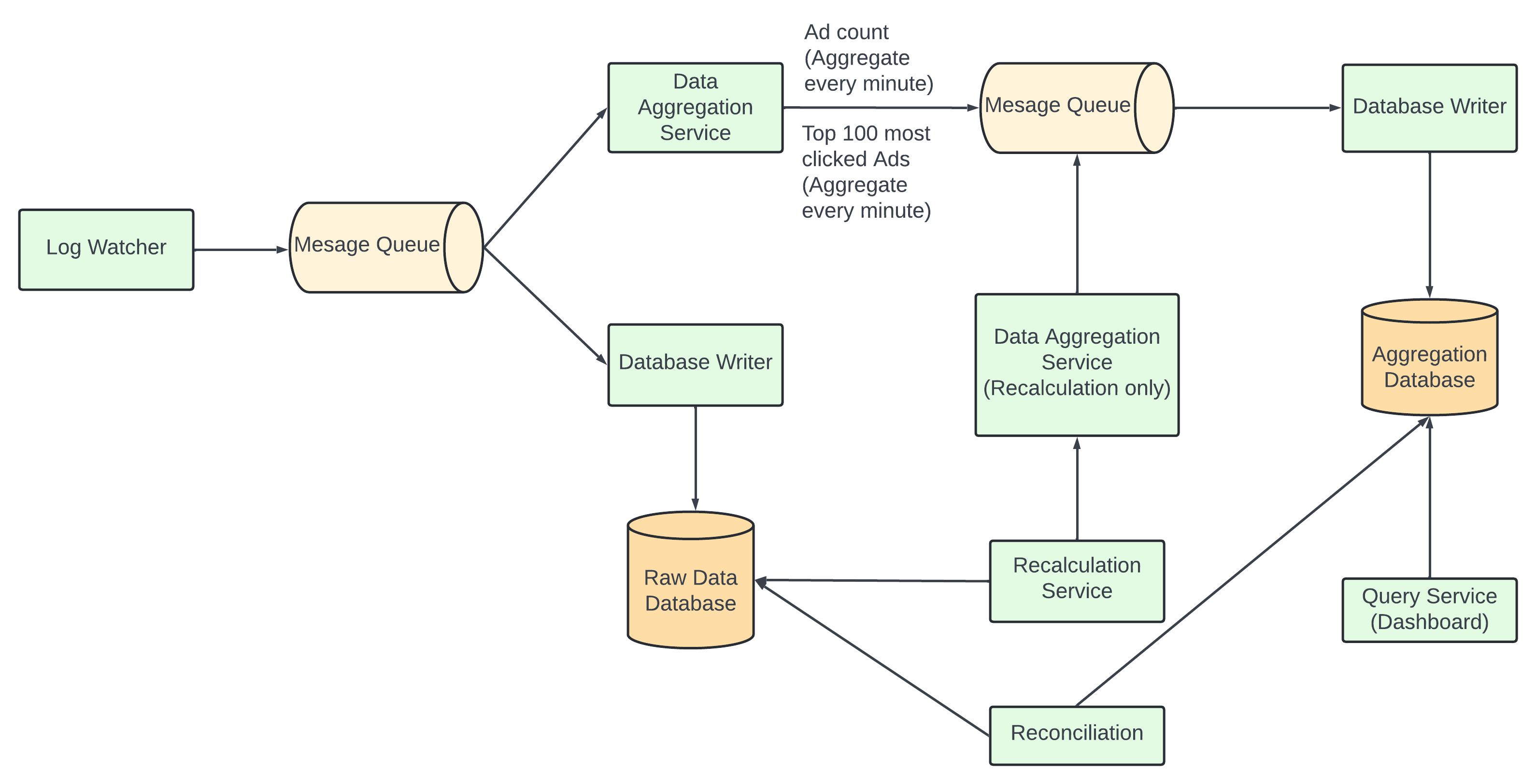
Not expected to know internal of many software - get the design correct.
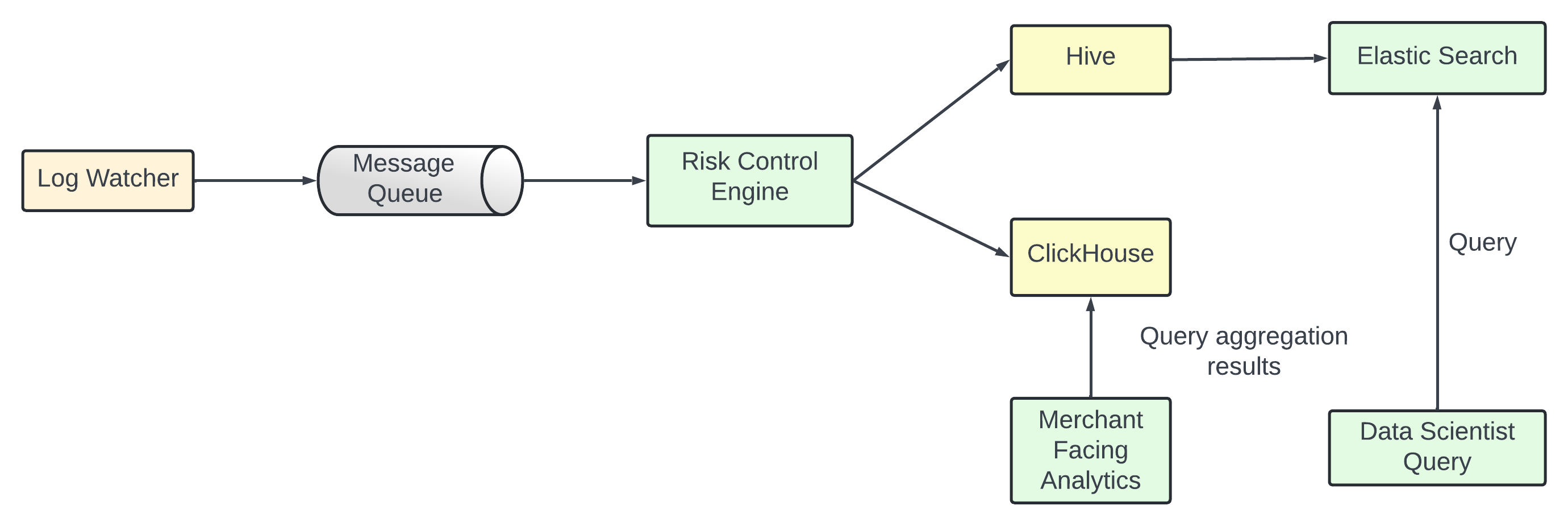
Another solution - store ad click data in Hive with an ElasticSearch layer built for faster queries.
Aggregation is useually done in db like ClickHouse or Druid.
Data model and API.
MapReduce to aggregate ad click event.
Scale message queue, aggregation service and database.
Mitigate hotspot issue.
Monitor the system.
Use reconciliation to ensure correctness.
Fault tolerance.
The system is typically a big data processing system - good to have experience with Apache Kafka, Apache Flink or Apache Spark.
Observation.
It is an extension of the Tiny URL - clicking ad or url - give the entire analytics to give the context.
It is also an extention of Stream Processing.
In this problem will give advertiser as much information as possible - ad_id, campaign_id, advertiser_id, time of entering originating page, time of click, originating_page_url, brower_information, Ip_address.
1kb per click and 10K QPS then total 10Mb data per second.
Counter - Using typical transactional Db like Dynamo Db for the problem to write the click and query - Single partition can handle upto 1Mb/sec of write and partition with ad_id the issue is not all add will be clicked with equal rate - It is like the celebrity problem.
The solution to repartition the data for the popular ad in order to spread across many shard. Adding some suffix to the ad_id and aggregate it later.
Another option to round robin the click on th epartition in db using load balancing - the issue is fetching the click for a given ad will be slow as need to go through all partition.
Handling lot of write from a single server - Apache Kafka - log based and each event is append at the end of the log file in disk - Disk write sequentially and not randomly and write are quick.
Topic partition in Kafka can handle 50MB/sec. Another advantage Kafka Replication.
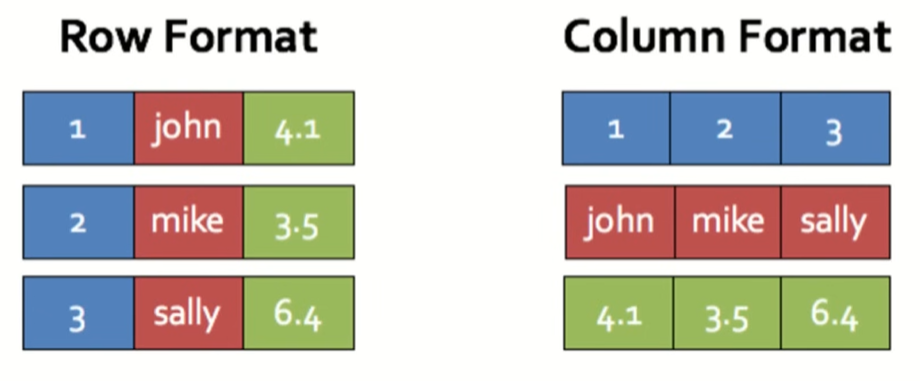
Now kafka should send data to a sytem to handle query - data warehouse or data lake. In contrast to transactional db like SQL(store data in row based storage), data warehouse store data in a columnar format and store data within a table column to gather on disk. Analytical data contains many column but query only need few and can access only imp column and less size.
Storing data in disk in sequential help in compression and similar data stay together. Operating in column batches and not one row at a time enable better CPU cache hit rate.
Kafka adding data to the data warehouse - Issue of deplicate - consumer after sending offset data 110 and did not get the confirmation and stops then next consumer will again send 110 to the data warehourse and the data will be duplicate - One way only send the max(offset) from the consumer and data warehouse to work with.
To see if a data is duplicate for malicious case - get the page url, ip address, ad_id, time when it was clicked and hash to get the key and then we can get the duplicate click.
Verify the click already exists before we put in the kafka. Use of transactional database is good in this case.
Row not present in database then add, row present then it is duplicate click.
Hashing is used to get the idempotent key and can scale across a cluster of database. The hash should be evenly distributed and no need to work on shard. More cick from same device can be removed by IP based rate limiter.
Okay lets not go deep - then how about removing user with VPN. The discussion will then go to a security point.
Db - partitioning - analytical db like BigQuery range based partitioning - clickHouse take hash of the partition key modulo the partition to get teh row data.
Data warehouse work good when the data is loaded in batches.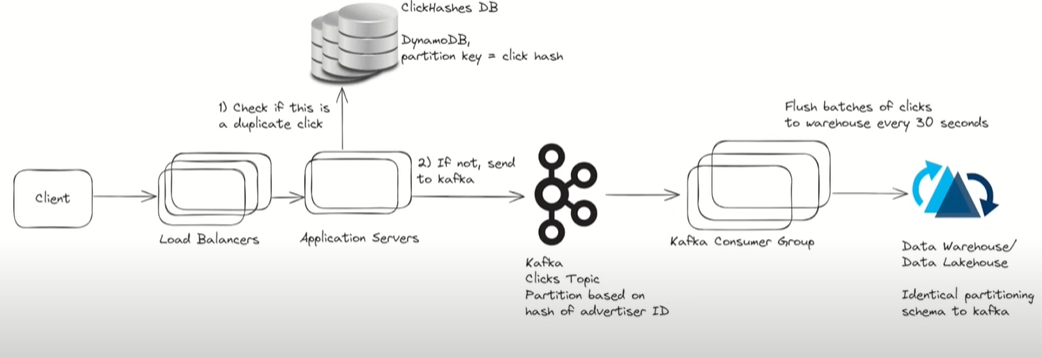
Scaling Kafka - Group of consumer with a same groupId then kafka distribute all partition to the consumer. Every time consumer pull the data and write to the data warehouse it commit the last offset back to the Kafka. When consumer stop before updating the offset and after writing to the database then the new consumer will take the work and set the latest commit offset in the db.
Computing Flush Interval
The industry standard the size of parquet file 256MB - 1GB.
Here we persist 10MB/sec of row data. After 10 mins we have = 10*60 for one minute = 10*\60*10 for 10 mins = 6GB of data.
Average compression size from avro to parquet = 2 to 10x depending on compression library so we will hit out target size.
We can flush out data every 15 mins to hit target file size.
Videos.
Hello Interview - https://youtu.be/Zcv_899yqhI?si=DUqLj4VSeW6wqJQs
Fight Club - https://youtu.be/_vK53SnrUjk?si=pRBzw6Fnlh6ir8XT