Kafka Stream 101
https://www.youtube.com/watch?v=gJUTErFyuY4&list=PLa7VYi0yPIH35IrbJ7Y0U2YLrR9u4QO-s
Kafka Streams plays a role. Filter message in the topic. Read one topic and enrich with data in another. Merge topics together into a third topic.
Kafka Stream is a functional Java API for doing stream processing on the data stored in Kafka.
Basic Operation.
Apache Kafka is an event streaming platform, distributed and fault tolerant as it replicate data across the storage nodes called broker.
The main part of broker is the log that holds the events and records and it is append only.
One Exmaple where we can sue KAfka Stream.
Widget application and getting all the detail in JSON.
{
"reading_ts": "2020-02-14T12:19:27Z",
"sensor_id": "aa-101",
"production_line": "w01",
"widget_type": "acme94",
"temp_celcius": 23,
"widget_weight_g": 100
}
Npw the requirement is to make the red color widget in a different topic. Say there is one producer and one consumer and the data of the red widget are storing in another topic. Using default Kafka work.
public static void main(String[] args) {
try (Consumer<String, Widget> consumer new KafkaConsumer <> (consumer Properties());
Producer<String, Widget> producer new KafkaProducer<> (producer Properties())) {
consumer.subscribe (Collections.singletonList("widgets"));
while (true) {
ConsumerRecords<String, Widget> records = consumer.poll(Duration.ofSeconds (5));
for (ConsumerRecord<String, Wigdet> record records) {
Widget widget = record.value();
if (widget.getColour().equals("red") {
Producer Record<String, Widget> producerRecord = new ProducerRecord<> (
"widgets-red", record.key(), widget);
producer.send (producer Record, (metadata, exception)-> {......} ); // Widget Topic.
// There should be another block for error handling.
The code will be long to get the details and try catch and then see all the event to add to the topic only to filter one data.
Using the Kafka Stream the code will be easy.
final StreamsBuilder builder = new StreamsBuilder();
// First thing is to use the StreamsBuilder object.
builder.stream ("widgets", Consumed.with(stringSerde, widgets Serde))
.filter((key, widget) -> widget.getColour.equals("red"))
.to ("widgets-red", Produced.with(string Serde, widgets Serde));
Create a stream from the Widget topic.
Kafka Stream works on event stream. When there are same key it update the value and store the new one. It is not same in Kafka stream as there are event and one key has no relation with other event.
When defining a Kafka Stream application we are defining a Processor Topology. Kafka Streams Processor Topology are the DAG which has the processing node and the edges that ignifes the flow of the streams.
StreamBuilder builder = new StreamBuilder();
KStream<String, String> firstStream =
builder.stream (inputTopic, Consumed.with (Serdes. String(), Serdes. String()));
First create an instanec of StreamBuilder class. Using it create a KStream building unit of kafka streams. The builder stream will take the input topic and the consumed figuration object. Taking the type of the key and value of the record.
Tranform the data - Mapping operation.
Filtering in kafka Stream.
public class BasicStreams (
public static void main(String[] args) throws IOException {
Properties streamsProps = new Properties();
try (FileInputStream fis = new FileInputStream(name:"src/main/resources/streams.properties")) {
streamsProps.load(fis);
}
streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "basic-streams");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("basic.input.topic");
final String outputTopic = streamsProps.getProperty("basic.output.topic");
// Retrieve the name of the input and output topics from the properties.
final String orderNumberStart = "orderNumber-";
KStream<String, String> firstStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), Serdes.String()));
firstStream.peek((key, value) -> System.out.println("key key + value + value)) // print the key and value as it in topology.
.filter((key, value) -> value.contains(orderNumberStart)) // filter to drop record where the value does not contain orderNumberString.
mapValues(value-> value.substring(value.indexOf("-")+1)) // mapValue operation to extract the number after the '-' character.
.filter((key,value) _> Long.parseLong(value)>1000) // filter to drop the record where the value is not more than 1000. In filter we put the record which we will pass.
.peek((key,value) -> System.out.println("key" + key + " value " + value))
.to(outputTopic, Produced.with(Serdes.String(), Serdes.String())); // the output topic to write the data.
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps);
TopicLoader.runProducer(); // It create the required topic on the cluster and produces some sample records.
KTables.
StreamBuilder builder = new StreamBuilder();
KTable<String, String> firstKTable =
builder.table (inputTopic,
Materialized.with (Serdes. String(), Serdes. String()));
Unlike KStream, KTable can be only subscribed to a single topic a once time. Table represents the latest value of each record. IN stream when new data appear with the update then new event is added here in ktable it will update the value inplace.
KTable will update thevalue so it needs to store the value and backed by state store. State Store are the copy of the events that are in the topic that the table is built from.
KTable we more care about like what is the latest value of the record. Data store in cache and it flushed to the table and the new value updated. Default value to commit.interval is 30 sec.
There are map, filter operator in KTable.
GlobalKTable - There is special kind of KTable.
StremBuilder builder = new StreamBuilder();
GlobalKTable<String, String> globalKTable = builder.globalTable(inputTopic, Materialized.with(Serdes.String(), Serdes.String()));
KafkaStream dealswith one partition at a time. GlobalKTable hold all the record across all the partition. Useful when want the data across the topic. Good for the data that does not update frequently like zip code, country code.
Example.
public class BasicStreams (
public static void main(String[] args) throws IOException {
Properties streamsProps = new Properties();
try (FileInputStream fis = new FileInputStream(name:"src/main/resources/streams.properties")) {
streamsProps.load(fis);
}
streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "ktable-application");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("basic.input.topic");
final String outputTopic = streamsProps.getProperty("basic.output.topic");
// Retrieve the name of the input and output topics from the properties.
final String orderNumberStart = "orderNumber-";
KTable<String, String> firstKTable = builder.table(inputTopic, Materialized.<String, String, KeyValueStore<Bytes, byte[]>> as("ktable-store").withKeySerde(Serdes.String()).withValueSerde(Serdes.String()));
// Filter to remove content which does not have orderNumber value.
firstKTable.filter((key, value) -> value.contains(orderNumberStarts))
.mapValues(value -> value.substring(value.indexOf("-")+1))
.filter(key,value)-> Long.parseLong(value)>1000)
.toStream()
.peek((key,value)->System.out.println("Output record - key+" value "+value)).to(outputTopic, Produced.with(Serdes.String(), serdes.String()));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps);
TopicLoader.runProducer();
kafkaStreams.start();
}
}
Data Serialization.
Kafka broker only understand the record as bytes.
Any object will be send to the byte for. Butes to Object - Deserialize. Object to Bytes - Serialize.
In Kafka Streams we work with Serdes for reading input bytes into expected object types.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> firstStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), customObjectSerde));
Here the Serdes.String() will understand that there is the key value which is in String and the value is customObject there should be an implementation of Serde in customObject.
KStream for the sink node to produce in outputTopic we use the Produced.with and for the source we add Consumed.with and take the parameter key and value.
KStream<String, CustomObject> modified Stream =
stream.filter( (key, value) -> value.startsWith("ID5"))
.mapValues (value -> new CustomObject (value));
modifiedStream.to ("output-topic", Produced.with (Serdes. String(), customObjectSerde);
StateStore we use the Materialized object to specify the Serde and useful when writing in to the local disk.
Serde<T> serde = Serdes.serdeFrom(new CustomSerializer<T>, new CustomDeserializer<T>);
In Serde we need to pass the CustomeSerializer and CustomDeserializer andto make the custome serializer and deserializer We have to implement the serializer and deserializer.
Kafka provides many serde by default and no need to implement. Pre-existing serdes - String, Integer, Double, Long, Float, Byte, ByteArray, ByteBuffer, UUID, Void.
Additional Sedes available for working with Avro, Protobuf, JsonSchema.
Avro - SpecificAvroSerde, GenericAvroSerde.
Protobuf - KafkaProtobufSerde.
JSONSchema - KafkaJsonSchemaSerde.
Schema Registry provide all the Serde in Kafka Stream.
JOINS
Kafka Stream join requires the record in the join should have same key.
Stream-Stream joins.
Combine two event streams into a new event stream.
Join of events based on a common key.
Records arrive within a defined window of time.
Possible to compute a new value type.
Keys are available in read-only mode can be used in computing the new value.
Stream-Table joins.
Any time new event come in the stream side will make the update based on the value in the KTable side.
KStream-KTable.
KStream-GlobalKTable.
Non-windowed joins.
Inner - Only if both sides are available is a record emitted.
Left-outer - The left side (KStream) always produces an output record Left-value + Right-value. Left-value+Null.
Only the stream side drives the join - new records arriving to the table (right-side) dont result in outputting a join result. When stream get the value it will add the new value.
GlobalKTable joins provide mechanism for determining the join-key from the Stream side key or value.
KTables are timestamp driven but GlobalKTables ae bootstrapped - results in different join semantics.
Table-Table joins.
The output will be reflected in the table.
GlobalKTable are useful as we dont have to see if the data are matched ahead of time. See the key and join with the streamside key.
GlobalKTable are bootstrap. Read the topic as soon as the data came into the GlobalKTable. KTable and join are timestamp driven. Event in KTable high timestamp are not going tojoin with KStream of lower timestamp.It only applicable when the timestamp is ahead of the time.
Stream-Stream Join.
Inner - Only if both sodes are available within the defined window is a joined result emitted.
Outer - Both sides always produce an output record.
Leftvalue+Right-value.
Left-value + Null.
Null + Right-value.
Left-Outer - The left side always produces an output recrd.
Left-value+Right-value.
Left-value+Null.
Example of Stream-Stream Joins.
KStream<String, String> leftStream = builder.stream("topic-A");
Kstream<String, String> rightStream = builder.stream("topic-B");
ValueJoiner<String, String, String> valueJoiner = (leftValue, rightValue) -> { return leftValue + rightValue;
}; // ValueJoiners will tell how to combine the left value and the right value.
leftStream.join(rightStream, valueJoiner, JoinWindows.of(Duration.ofSeconds(10)));
Example of the Streams Join. Here we are using static method to get the Serdes form the Avro records. We can use it as a utility method.
public class StreamsJoin {
static < extends SpecificRecord> SpecificAvroSerde<> getSpecificAvroSerde(final Map<String, Object> serdeConfig) {
final SpecificAvroSerde<> specificAvroSerde = new SpecificAvroSerde<>();
specificAvroSerde.configure(serdeConfig, isSerde ForRecord Keys: false);
return specificAvroSerde;
}
// The utility method to load the properties.
public static void main(String[] args) throws IOException {
final Properties streamsProps = StreamsUtils.loadProperties():
streamsProps.put(StreamsConfig.APPLICATION_ID CONFIS, "joining-streams");
StreamsBuilder builder = new StreamsBuilder();
final String streamOneInput = streamsProps.getProperty("stream_one.input.topic");
final String streamTwoInput = streamsProps.getProperty("stream_two.input.topic");
final String tableInput = streamsProps.getProperty("table.input.topic");
final String outputTopic streams Props.getProperty("joins.output.topic");
final Map<String, Object> configMap = StreamsUtils.propertiesToMap (streamsProps);
// Create the Serde for all the streams and the tables.
SpecificAvroSerde<ApplicationOrder> applianceSerde = getSpecificAvroSerde(configMap);
SpecificAvroSerde<ApplicationOrder> applianceSerde = getSpecificAvroSerde(configMap);
SpecificAvroSerde<ElectronicOrder> electronicSerde = getSpecificAvroSerde(configMap);
SpecificAvroSerde<CombinedOrder> combinedSerde = getSpecificAvroSerde(configMap);
SpecificAvroSerde<User> userSerde = getSpecificAvroSerde(configMap);
// Create the ValueJoiner by the Stream-Stream join by the left and right side of the join.
// Stream is the output of the Stream-Stream join. It is a left outer join as the right side data might not exists.
ValueJoiner<ApplianceOrder, Electronicürder, CombinedOrder> orderJoiner =
(applianceOrder, electronicorder) -> CombinedOrder.newBuilder()
setApplianceOrderId(applianceûrder.getOrderId())
.setApplianceId(applianceorder.getApplianceId())
.setElectronicOrderId(electronicOrder.getOrderId())
.setTime(Instant.now().toEpochMilli())
.build();
// Create the ValueJoiner for the Stream-Table join.
ValueJoiner<CombinedOrder, User, CombinedOrder> enrichmentJoiner =>
(combined, user) -> {
if (user != null) {
combined.setUserName(user.getName());
}
return combined;
};
// Create the applianeOrder Stream.
KStream<String, ApplianceOrder> applianceStream =
builder.stream(streamOneInput, Consumed.with(Serdes.String(), applianceSerde));
KStream<String, ElectronicOrder> electronicStream =>
builder.stream (streamTwoInput, Consumed.with(Serdes.String(), electronicSerde));
KTable<String, User> userTable =
builder.table(tableInput, Materialized.with(Serdes.String(), userSerde));
// Call the stream-stream join and call the join method on the appliance stream left side on the primary stream in join. Right side electronicStream in the join and then the OrderJoiner. Specify a join window of 30 mins. The right side record must have a timestamp within 30 mins before or after the timestamp of the left side of the same key.
KStream<String, CombinedOrder> combinedStream = applianceStream.join(
electronicStream, orderJoiner, Joinwindows.of(Duration.ofMinutes(30)),
StreamJoined.with(Serdes.String(), applianceSerde, electronicSerde))
.peek((key, value) -> System.out.println("key "+ key + value value));
combinedStream.leftJoin(
userTable,
enrichmentJoiner,
Joined.with(Serdes.String(), combinedSerde, userSerde))
.peek((key, value) -> System.out.println("key" + key + value + value))
.to (outputTopic, Produced.with(Serdes.String(), combinedSerde));
KafkaStreams kafkaStreams = new KafkaStreams (builder.build(), streamsProps);
TopicLoader.runProducer();
kafkaStreams.start();
// StreamJoined.with(Serdes.String(), applianceSerde, electronicSerde))
// (key, left side, right side)
}
Stateful Operation.
Stateless Operations - Great for operations where you dont need to remember. Filter - drop records that dont match the condition.
Remember previous results - How many times has a particular customer logged in? What is the total sum of tickets sold?
For those situations where the previous state of an event is imporatnt streams offers stateful operations. Example - count, aggregation, reduce.
StreamBuilder builder = new StreamBuilder();
KStream<String, Long> myStream = builder.stream("topic-A");
// Create the Stream.
Reduce<Long> reducer = (longValueOne, longValueTwo) -> longValueOne + longValueTwo;
myStream.groupByKey().reduce(reducer, Materialized.with(Serdes.String(), Serdes.Long())).toStream().to("output-topic");
// In any Stateful Operation there will be a GroupByKey() all key will match together.
// Materialized tell the Kafka Operator how to store the data in the State store.
// The key is String and the Value is Long.
Example of Aggregation.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> myStream builder.stream("topic-A");
Aggregator<String, String, Long> character CountAgg = (key, value, charCount) -> value.length() + charCount; // Counting the number of characters we have seen.
myStream.groupByKey().aggregate (() -> 0L, characterCountAgg, Materialized.with (Serdes.String(), Serdes.Long())).toStream().to("output-topic");
// GroupByKey in stateful operator.
// The first argument in the aggregate is the initializer. Initializer will tell the aggregate how to start the value the initial character count.
Aggregations.
public class StreamsAggregate{
public static void main(String[] args) throws IOException {
final Properties streamsProps = StreamsUtils.loadProperties():
streamsProps.put(StreamsConfig.APPLICATION_ID CONFIG, "aggregate-streams");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("aggregate.input.topic");
final String streamTwoInput = streamsProps.getProperty("aggregate.output.topic");
final Map<String, Object> configMap = StreamsUtils.propertiesToMap (streamsProps);
SpecificAvroSerde<ElectronicOrder> electronicSerde = StreamsUtils.getSpecificAvroSerde(configMap);
final KStream<String, ElectronicOrder> electronicStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), electronicSerde));
electronicStream.groupByKey().aggregate(()->0.0,
(key, order, total) -> total + order.getPrice(), Materialized.with(Serdes.String(), Serdes.Double())).toStream().peek((key, value) -> System.out.println("Key " + key + " Value = " + value)).to(outputTopic, Produced.with(Serdes.String(), Serdes.Double()));
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps);
TopicLoader.runProducer();
kafkaStreams.start();
// StreamJoined.with(Serdes.String(), applianceSerde, electronicSerde))
// (key, left side, right side)
}
}
Windowing.
Aggregations continue to build up over time. Windowing gives snapsort of an aggregate ithin a given timeframe.
4 types of windows - Tumbling, Hopping, Session, Sliding.
KStream<String, String> meStream = builder.stream("topic-A");
myStream.groupByKey().count().toStream().to("output")
// count operator track the number of record. It will keep growing and it contain the history of the topic.
// The count for a particular window.
Hopping Window - bounded over time and a fixed start and end time.
KStream<String, Strin> myStream = builder.stream("topic-A");
Duration windowSize = Duration.ofMinutes(5);
Duration advanceSize = Duration.ofMinutes(1);
TimeWindows hoppingWindow = TimeWindows.of(windowSize).advanceBy(advanceSize);
myStream.groupByKey().windowedBy(hoppingWindow).count();
It need to get the windowSize and the advanceSize.
AdvanceSize determine how the window advances. It value 1 then the window size will go 0 to 5 then 1 to 6. AdvanceSize less than windowSize there are many duplicate values.
Tumbling window - AdvanceSize is equal to the WindowSize. No duplicates.
KStream<String, Strin> myStream = builder.stream("topic-A");
Duration windowSize = Duration.ofSeconds(30);
TimeWindows tumblingWindow = TimeWindows.of(windowSize);
myStream.groupByKey().windowedBy(tumblingWindow).count();
Session Window - Window start and window end. The window boundary is determined by the event.
KStream<String, Strin> myStream = builder.stream("topic-A");
Duration inactivityGap = Duration.ofMinutes(5);
myStream.groupByKey().windowedBy(SessionWindows.with(inactivityGap)).count();
Sliding Window -
KStream<String, Strin> myStream = builder.stream("topic-A");
Duration timeDifference = Duration.ofSeconds(2);
Duration gracePeriod = Duration.ofMillis(500);
myStream.groupByKey().windowedBy(SlidingWindows.withTimeDifferenceAndGrace(timeDifference, gracePeriod)).count();
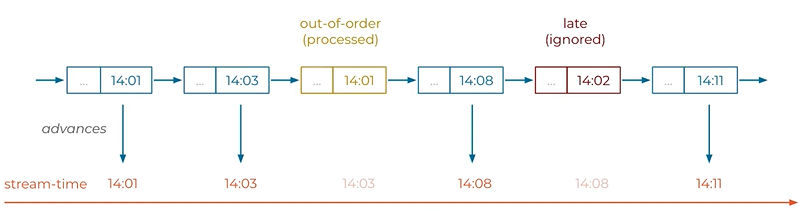
Grace period - Event coming within the window size will be added to the window and records outside the window will be discarded. There is grace window defined in any of the window means the time you will accept the record after the window time has ended.
public class StreamsAggregate{
public static void main(String[] args) throws IOException {
final Properties streamsProps = StreamsUtils.loadProperties():
streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "windowed-streams");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("windowed.input.topic");
final String streamTwoInput = streamsProps.getProperty("windowed.output.topic");
final Map<String, Object> configMap = StreamsUtils.propertiesToMap (streamsProps);
SpecificAvroSerde<ElectronicOrder> electronicSerde = StreamsUtils.getSpecificAvroSerde(configMap);
final KStream<String, ElectronicOrder> electronicStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), electronicSerde)).peek((key, value) -> System.out.println("Key " + key + " Value = " + value));
electronicStream.groupByKey().windowedBy(Timewindows.of(Duration.ofHours(1)).grace(Duration.ofMinutes(5))).agregate(()->0.0,(key, order, total) -> total + order.getPrice(), Materialized.with(Serdes.String(), Serdes.Double())).suppress(untilWindowCLoses(unbounded())).toStream().map((wk,value)->KeyValue.pair(wk.key(),value)).peek((key,value)->System.out.println("Key "+key+" value = "+value)).to(outputTopic, Produced.with(Serdes.String(), Serdes.Double()));
// Tumbling window of 1 hour and grace period of 5 mins. Materialized to store in state store. Suppress all the message into the window till it open. The toStream() convert the KTable to KStream. The map to the window key to the underlying record key.
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps);
TopicLoader.runProducer();
kafkaStreams.start();
}
}
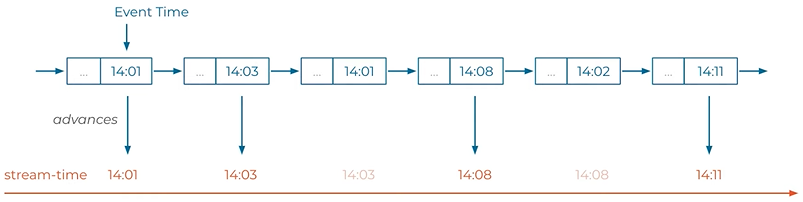
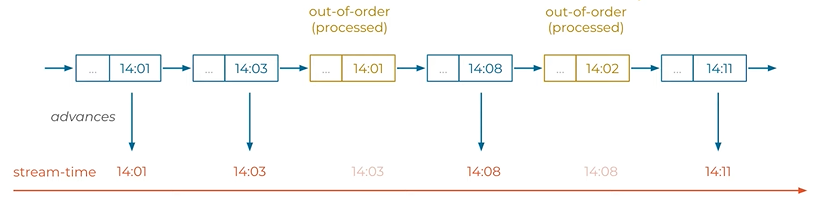
Time Concept.
The kafka message forma has a dedicated timestamp field.
Event-time - A producer including Kafka Streams library automatically set this timestamp field if user does not add it. Timestamp is the current world clock time of the producer event environment when the event is created.
Ingestion-time - The time that is configured by the Kafka broker to set the time step failed where an event is appended or stored in to the topic. Timestamp is the current wall clock time of the broker environment.
Defining custom TimeStampExtractor then implement the TimeStampExtractor interface.
public class StreamsTimeStampExtractor{
public static void main(String[] args) throws IOException {
final Properties streamsProps = StreamsUtils.loadProperties():
streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "extractor-windowed-streams");
StreamsBuilder builder = new StreamsBuilder();
final String inputTopic = streamsProps.getProperty("extractor.input.topic");
final String streamTwoInput = streamsProps.getProperty("extractor.output.topic");
final Map<String, Object> configMap = StreamsUtils.propertiesToMap (streamsProps);
SpecificAvroSerde<ElectronicOrder> electronicSerde = StreamsUtils.getSpecificAvroSerde(configMap);
final KStream<String, ElectronicOrder> electronicStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), electronicSerde)).peek((key, value) -> System.out.println("Key " + key + " Value = " + value));