Topic4GoogleCloudDataflow
GCP Data flow Architecture.
Overview of the Dataflow Runner Architecture. Overview of Dataflow Runner core features. GCP Horizontal services integration.
Beam pipeline runs in the dataflow runner.
Beam pipeline integrated to the other part of the GCP
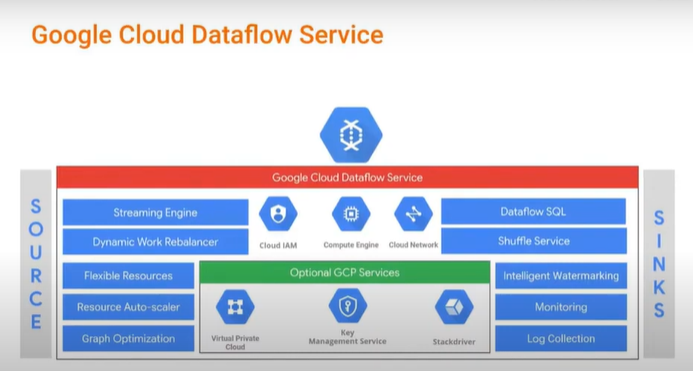
Main aspect of Dataflow. Graph Optimization, Resource Auto Scaler, Monitoring, Logging.
Other integration - Cloud IAM, Compute Engine, Cloud Network.
Graph Optimization - Compiler Optimization.
Producer-Consumer Fusion. Sibling Fusion.
Monitoring.
Dataflow job page. Enhanced observalibility features.
The Ui will show the dataflow job id and we can see the steps of the beam pipeline and the source and sink. There will be some job metric, cpu usage, memory usage. The steps details will be shown. The bottom will be the logging.
The detial of the workers executing the compute engine jobs. Workers are the VMS.
Integration.
At a high level there is a beam pipeline written and then submit to the regional endpoint.
Regional Endpoint is the primary worker. - It is not the worker that is working it will store the reource provisioning and doing the task like what needs to be done and provision the work.
At the same time the pipeline will be send to the GCS like the Google Storage.
GCS will store the common resources that the worker is actually executing the work will need to access.
First submitting the pipeline to the primary worker Regional Worker and it will lease out to the secondary worker which will actually do the work. The secondary workers are all teh compute engine Vms.
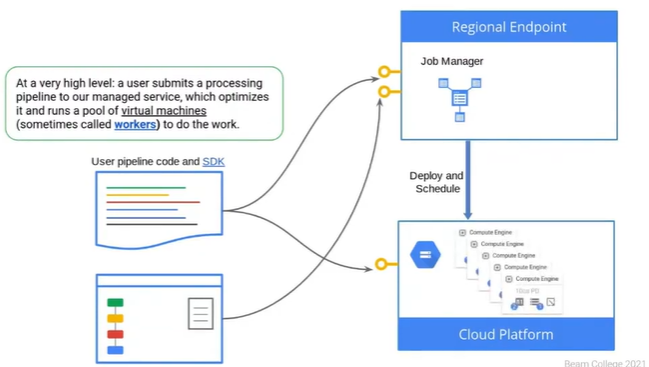
Region Endpoint. Deploy and controls Dataflow workers and stores Job Metadata. Region is us-contral1 by default, unless explicitly set using the region parameter.
Zone. It is the secondary dataflow worker. It is the compute engine vms. Defines the locations of the Datflow workers. Defaults to a zone in the region selected based on available zone capacity. It can be overridden using the zone parameter.
The zone does not need to be in the same region endpoint. Reasons you may want to do this includes the security and compliance, data locality, resilience in geographic separation.
If you override the zone and the zone is in a different region than the region at any point that will be negative impact on performance, network traffic and network latency.
Dataflow and Cloud IAM.
Identity Access Management.
There are minimum 2 service account that needs to be provisioned.
Dataflow service account - service-<project-number>@dataflow- service-producer-prod.iam.gserviceaccount.com.
It is mapping to the primary worker.
Used for worker creation, monitoring, etc.
Controller Service Account -
<project-number>-compute@developer.gserviceaccount.com
Mapped to the secondary workers.
Used by the worker to access resources needed by the pipeline. For example, files on the Google Cloud Storage bucket.
Can be operated in using –serviceAccount.
The third service account could be used to actually submit the pipeline to the service.
Feature introduced in cloud dataflow recently.
Batch Dynamic work redistribution.
In the distributed data processing there is a common problem of Hotkeys issue. Primary worker assign a lot of work to one seondary worker and not to the other secondary worker. Delap the job. It is called the hotkey issue and sharding. There is Batch dynamic work distribution that will redistribute hotkeys for more even workload distribution. Fully automated.
Another feature.
Dataflow shuffle service for the batch job. Pipeline running and there is a source and sink and there is a resource intensive work It will send to the shuffle service and the shuffle service will do the computation and the dataflow pipeline will continue the work.
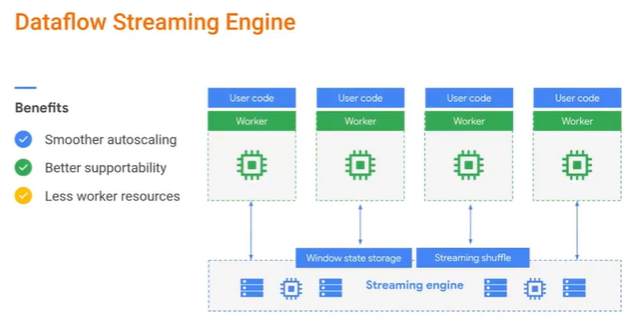
data streaming engine.
Same thing. When there is a bit resource intensive work, it will send it to the data for streaming engine and it will do the competition and it will send back to the datflow pipeline.
Dataflow SQL UI.
SQL code to trigger the data flow.
Data flow Features.
Standard Vm and Preemptive Vms - short lived vms. We can make a combination of the standard beam and the preemptible PM for the data flow jobs.
Flexible resource schedule. FlexibleRS reduces batch processing costs by using advanced scheduling techniques, the Cloud Data flow shuffle service, and a combination of preemptive VMs and regular VMs.
Jobs with flexRS new service-based Cloud Dataflow Shuffle for joining grouping.
Dataflow Template.
Select 20+ Google provided templates or use your own. No need to recompile the code to run the jobs. Popular ETL sources and sinks. Streaming and batch modes. Launch from gcp or pop sub trousers.